
Berita
Penelitian Nous Falls Hermes 4 AI Model yang melampaui chatgpt tanpa pembatasan konten

Ingin lebih banyak visi yang cerdas dari kotak masuk Anda? Berlangganan buletin mingguan kami untuk mendapatkan apa yang hanya terkait dengan lembaga AI, data dan pemimpin keamanan. Berlangganan sekarang
Pencarian nousMemulai kecerdasan buatan rahasia yang muncul sebagai suara perintis dalam gerakan kecerdasan buatan Hermes 4 Pada hari Senin, keluarga model bahasa besar yang diklaim perusahaan dengan kinerja sistem cadangan terkemuka dapat mencocokkan kontrol pengguna yang belum pernah terjadi sebelumnya dan pembatasan konten minimum.
Versi ini merupakan eskalasi besar dalam pertempuran antara pendukung AI open source dan perusahaan teknologi utama tentang siapa yang harus mengendalikan kemampuan kecerdasan buatan yang maju. Tidak seperti model dari OpenaiDan GoogleAtau priaHermes 4 dirancang untuk menanggapi hampir semua permintaan tanpa pegangan tangan yang telah menjadi standar dalam sistem kecerdasan buatan.
Nous Research Hermes 4, garis terakhir pemikiran hibrida.https://t.co/e5w9hburb
Hermes 4 tergantung pada warisan kami dari model penyelarasan pengguna dengan kemungkinan menghitung waktu tes yang diperluas.
Perhatian khusus telah diberikan untuk membuat model yang kreatif dan menarik … pic.twitter.com/52vjnvrdwm
– Penelitian Nous (NousResearch) 26 Agustus 2025
Nous Research mengumumkan di X (Twitter): “Hermes 4 tergantung pada warisan kami dari model pengguna dengan kemungkinan memperluas waktu tes.” “Perhatian khusus telah diberikan untuk membuat model kreatif dan menarik untuk berinteraksi dengan sensor, penyelarasan netral sambil mempertahankan keadaan matematika di tingkat teknis, pengkodean, dan pemikiran model berat terbuka.”
Bagaimana mengungguli “Hermes Thinking” di Hermes 4 atas chatgpt dan clade atas standar matematika
Hermes 4 Apa yang disebut penelitian nous “pemikiran hibrida”, yang memungkinkan pengguna untuk beralih antara respons cepat dan proses berpikir yang lebih dalam selangkah demi selangkah. Saat diaktifkan, model menghasilkan pemikiran internal mereka dalam bidang khusus
Kecerdasan buatan membatasi batasnya
Tutup daya, biaya tinggi simbol, dan keterlambatan inferensi dibentuk kembali. Bergabunglah dengan salon eksklusif kami untuk menemukan bagaimana perbedaan besar:
- Mengubah energi menjadi keuntungan strategis
- Mengajar penalaran yang efektif untuk keuntungan produktivitas nyata
- Membuka Pengembalian Investasi Kompetitif dengan Sistem Kecerdasan Buatan Berkelanjutan
Mengamankan tempat Anda untuk tinggal di latar depan: https://bit.ly/4mwngngo
Pencapaian teknis sangat bagus. Dalam Tes, model Bachelors Hermes 4 terbesar mencatat 405 miliar dari 96,3 % di Pengukuran Math-500 Dalam Mode Berpikir dan 81,9 % tentang Tantangan AIME’24 Kompetisi Matematika Kinerja yang bersaing atau melampaui banyak sistem properti yang harganya jutaan untuk dikembangkan.
“Tantangannya adalah membuat efek penggunaan berpikir Rohan Paul di xMenyoroti salah satu terobosan teknis dalam versi.
Mungkin yang paling menonjol, Hermes 4 Dia mencapai tingkat tertinggi dari semua model yang diuji pada “Refusalbench”, penelitian baru yang dibuat untuk mengukur berapa kali sistem kecerdasan buatan menolak untuk menjawab pertanyaan. Model ini mencatat 57,1 %dalam mode berpikir, sangat mengungguli GPT-4O (17,67 %) dan Clauds Sonnet 4 (17 %).
Di dalam Dataforge dan Atropos: Penetrasi Sistem Pelatihan Di Balik Kemampuan Hermes 4
Di balik kemampuan Hermes 4 terletak infrastruktur pelatihan lanjutan Pencarian nous Ini telah berkembang selama beberapa tahun. Model telah dilatih menggunakan dua sistem baru: DataforgeGenerator data industri berdasarkan grafik, dan AtropApi penguatan open source.
Dataforge Ini menciptakan data pelatihan melalui apa yang perusahaan gambarkan sebagai “aspek acak” melalui grafik terpandu, yang mengubah data pelatihan sederhana menjadi contoh -contoh instruksi kompleks tindak lanjut. Sistem, misalnya, dapat mengambil artikel Wikipedia dan mengubahnya menjadi lagu rap, kemudian membuat pertanyaan dan jawaban berdasarkan transformasi ini.
AtropSementara itu, ini bekerja seperti ratusan lingkungan pelatihan khusus di mana model kecerdasan buatan mempraktikkan keterampilan khusus – matematika, pengkodean, penggunaan alat, dan penulisan kreatif – hanya komentar saat memproduksi solusi yang benar. Pendekatan “sampel penolakan” memastikan bahwa hanya respons yang diverifikasi berkualitas tinggi yang membuatnya dalam data pelatihan.
Atropos adalah bingkai pembelajaran penguatan
Atropos adalah lingkungan untuk belajar meningkatkan sumber terbuka oleh Nous yang berisi ratusan “pusat kebugaran” (seperti matematika, pengkodean, permainan, alat, dan visi) untuk melatih dan mengevaluasi jalur LLM melalui sesi RL.
Dengan kata lain … pic.twitter.com/fjxaqklez
– Tommy (@shaghnessy119) 26 Agustus 2025
“Nous lingkungan ini untuk membuat pengumpulan data untuk Hermes 4!” Menyusun Tommy ShunisiKapitalisme proyek di Delphi Ventures Yang diinvestasikan dalam penelitian nous. “Segala sesuatu dalam kumpulan data berisi 3,5 juta sampel berpikir dan 1,6 juta sampel yang tidak dispread! Hermes telah dilatih pada data RL, bukan hanya set pertanyaan dan jawaban data yang diperbaiki!”
Proses pelatihan membutuhkan 192 nvidia Unit Pemrosesan Grafik B200 Dan 71.616 jam GPU dari model terbesar – investasi akun penting tetapi secara belum pernah menjelaskan bagaimana teknologi khusus dapat bersaing dengan sejumlah besar raksasa teknologi.
Mengapa Penelitian Nous percaya bahwa pegangan tangan kecerdasan buatan “menjengkelkan seperti neraka” dan melukai inovasi
Pencarian nous Dia membangun reputasinya di atas filosofi yang menempatkan kontrol pengguna atas kebijakan konten perusahaan. Model perusahaan dirancang untuk “diarahkan”, yang berarti bahwa mereka dapat ditangkap atau dituntut untuk bertindak dengan cara tertentu tanpa batasan keamanan yang kuat yang menjadi ciri sistem kecerdasan buatan komersial.
“Hermes 4 tidak diatasi sebelum evakuasi tanggung jawab, aturan, kehati -hatian yang berlebihan yang mengganggu neraka dan menyakiti inovasi dan kemudahan penggunaan,” kata Shunisi di utas terperinci. “Jika sumbernya terbuka, tetapi menolak semua permintaan yang tidak berarti. Ini bukan masalah dengan Hermes 4.”
Hermes 4 belum terbunuh karena evakuasi tanggung jawab, aturan, dan kehati -hatian yang berlebihan yang mengganggu neraka, menyakiti inovasi dan kemudahan penggunaan.
Hermes 4 70B tidak seperti spektrum vs openAi open source. Ini juga ~ 4x lebih terbuka versus chatgpt 4o!
Jika terbuka … pic.twitter.com/q5rpx1oozo
– Tommy (@shaghnessy119) 26 Agustus 2025
Dia mengambil pendekatan ini Pencarian nous Adalah umum di antara para peneliti dan pengembang yang menginginkan fleksibilitas maksimum, tetapi juga menempatkan perusahaan di pusat diskusi saat ini tentang integritas kecerdasan buatan dan konten moderat. Sementara model dapat digunakan secara teoritis untuk tujuan berbahaya, Nous Research berpendapat bahwa transparansi dan pengendali pengguna lebih disukai untuk mempertahankan gerbang perusahaan.
Perusahaan Laporan Teknis,, yang dirilis bersama model, memberikan rincian yang belum pernah terjadi sebelumnya tentang proses pelatihan, hasil evaluasi, dan bahkan output teks aktual dari tes standar. “Kami percaya bahwa laporan ini mendefinisikan standar baru untuk transparansi dalam pengukuran,” kata perusahaan itu.
Bagaimana startup kecil bersaing dengan 192 unit pemrosesan grafis dengan anggaran teknologi besar AI adalah miliaran dolar
Hermes 4Versi hadir dalam momen penting dalam industri kecerdasan buatan. Sementara perusahaan teknologi besar telah menuangkan miliaran dolar untuk mengembangkan sistem kecerdasan buatan yang semakin semakin meningkat, gerakan open source yang semakin meningkat berpendapat bahwa kemampuan ini tidak boleh dikendalikan oleh segelintir perusahaan.
Bulan -bulan terakhir telah menyaksikan perkembangan besar dalam kecerdasan buatan sumber terbuka, dengan model seperti meta LAMA 3.1Dan R1 DeepseekDan Ali Baba Qwen Seri pencapaian kinerja yang bersaing dengan sistem properti. Hermes 4 mewakili langkah lain dalam kemajuan ini, terutama di bidang pemikiran – karena kekuatan yang panjang untuk sistem tertutup O1 Openai.
“Pertama, Nous adalah startup yang mencakup lusinan orang yang sangat berbakat”, ” Catatan Shunisi. “Mereka tidak memiliki pengeluaran CAPEX tahunan senilai $ 100 miliar untuk membeli Paskah atau 1.000 karyawan, dan meskipun mereka terus meluncurkan model inovatif dan kecepatan gila.”
Startup, yang Pembiayaan $ 65 juta cepat Awal tahun ini memimpin modelDan itu dikembangkan JiwaSistem pelatihan terdistribusi yang bertujuan mengoordinasikan pelatihan kecerdasan buatan melalui komputer internet menggunakan teknologi blockchain.
Reformasi teknis yang mencegah Hermes 4 memikirkan episode yang tak ada habisnya
Satu Hermes 4Kontribusi teknis yang paling penting membahas model pemikiran: proses berpikir panjang yang berlebihan. Para peneliti telah menemukan bahwa model kredit mikro 14 miliar orang akan mencapai periode maksimum 60 % dari waktu ketika berpikir adalah, dan mereka terutama berhenti dalam episode pemikiran yang tak ada habisnya.
Solusi mereka menjamin fase pelatihan kedua yang mengajarkan model untuk berhenti berpikir tepat tentang 30.000 simbol, yang mengurangi generasi pelayaran sebesar 65-79 % sambil mempertahankan sebagian besar kinerja berpikir. Teknik “kontrol panjang” dapat menjadi berharga bagi komunitas penelitian kecerdasan buatan yang lebih luas.
“Model yang lebih kecil (<14b) cenderung berpikir tentang berpikir ketika disuling, tetapi model yang lebih besar melakukannya Muyu ada di xMenyoroti visi laporan teknis.
Tetapi, Hermes 4 Dia masih menghadapi batasan umum dalam model open source. Meskipun kinerja standar yang mengesankan, model membutuhkan sumber daya matematika yang besar untuk menjalankannya dan mungkin tidak bertepatan dengan kemudahan penggunaan atau keandalan layanan kecerdasan buatan untuk banyak aplikasi.
Di mana Hermes 4 mencoba dan berapa biayanya dibandingkan dengan chatgpt dan claud
Pencarian nous Saya telah membuat Hermes 4 Tersedia melalui beberapa saluran, yang mencerminkan filosofi open source. Bobot khas dapat diunduh secara bebas dalam menghadapi pelukan, sementara perusahaan juga menyediakan akses ke antarmuka pemrograman aplikasi melalui antarmuka obrolan yang telah direnovasi dan kemitraan dengan penyedia inferensi seperti chues, nebius dan luminal.
“Anda dapat mencoba Hermes 4 dalam antarmuka pengguna Nous Nous yang baru terbarukan,” perusahaan mengumumkan, menyoroti fitur -fitur seperti reaksi paralel dan sistem memori.
Untuk pengguna dan peneliti lembaga, model tersebut mewakili alternatif yang menarik dan potensial untuk membayar akses API ke sistem properti, terutama untuk aplikasi yang membutuhkan kustomisasi tingkat tinggi atau berurusan dengan konten sensitif.
Gambaran terbesar: Apa arti Hermes 4 untuk masa depan pengembangan kecerdasan buatan
melepaskan Hermes 4 Lebih dari sekadar meluncurkan model AI lain – ini adalah pernyataan tentang siapa yang harus mengendalikan masa depan kecerdasan buatan. Dalam industri yang semakin didominasi segelintir raksasa teknologi dengan sumber daya yang hampir tidak terbatas, penelitian Nous telah membuktikan bahwa inovasi masih bisa datang dari tempat yang tidak terduga.
Pendekatan perusahaan menimbulkan pertanyaan dasar tentang perbedaan antara keselamatan dan kemampuan, antara kontrol perusahaan dan kebebasan pengguna. Sementara perusahaan teknologi besar berpendapat bahwa konten moderat dan studi keselamatan yang akurat diperlukan untuk menyebarkan kecerdasan buatan yang bertanggung jawab, penelitian Nous mengklaim bahwa transparansi dan agen pengguna lebih penting daripada pembatasan yang dikenakan pada perusahaan.
Apakah filosofi ini pada akhirnya akan terbukti bermanfaat atau bermasalah yang harus kita lihat. Tetapi ada satu hal tertentu: Hermes 4 telah menunjukkan bahwa masa depan kecerdasan buatan tidak akan ditentukan hanya oleh perusahaan yang memiliki kantong terdalam.
Di bidang di mana barang -barang mustahil kemarin menjadi barang, penelitian nous telah membuktikan bahwa satu -satunya hal paling berbahaya dari kecerdasan buatan yang mengatakan tidak dapat siap untuk mengatakan ya.

Tautan sumber

baruAnda sekarang dapat mendengarkan artikel Fox News!
Natalya Neidhart adalah salah satu nama terbesar dalam gulat profesional.
Dia adalah cucu dari pelatih gulat legendaris Stu Hart, putri Jim “The Anvil” Neidhart dan keponakan dari Bret Hart dan mendiang Owen Hart. Dia telah menjadi tokoh terkemuka di divisi wanita WWE sejak 2007 dan telah berkembang menjadi salah satu bintang paling populer di perusahaan tersebut.
KLIK DI SINI UNTUK CAKUPAN OLAHRAGA LEBIH LANJUT DI FOXNEWS.COM
Natalya Neidhart menghadiri pemutaran perdana “WWE Monday Night Raw” di Los Angeles di Netflix di Intuit Dome pada 6 Januari 2025 di Inglewood, California. (JC Oliveira/Getty Images)
Neidhart berbicara tentang semua cobaan dan kesengsaraan yang dia hadapi dalam hidupnya dalam otobiografinya, “The Last Hart Beating: From the Dungeon to WWE.” Neidhart membawa pembaca pada perjalanan dari awal mulanya dalam gulat profesional melalui semua momen tragis yang dialami keluarganya, termasuk kematian tragis ayah dan pamannya.
Dia mengatakan kepada Fox News Digital bahwa menulis buku adalah cara dia keluar dari zona nyaman dan menantangnya di level yang berbeda.
“Hal terpenting dalam menulis buku ini hanyalah tentang mencapai tujuan baru, tantangan baru, hal baru,” jelasnya. “Menulis buku adalah sesuatu yang selalu ingin aku lakukan, tapi aku juga takut untuk melakukannya. Setahun terakhir, aku benar-benar menaruh perhatian untuk menghadapi tantangan yang membuatku takut. Aku sudah berpikir untuk melakukan hal-hal seperti…itu bahkan bukan hal yang sangat membuatku takut, tapi hanya melakukan hal-hal di luar zona nyamanku, masuk ke dalam situasi yang tidak mudah seperti mengambil kepribadian baru atau mengerjakan proyek baru.”
“Menulis buku adalah sesuatu yang selalu ingin saya lakukan tetapi terus menundanya karena saya berpikir, ‘Jika saya menulis buku, saya hanya ingin buku itu sempurna.’
Neidhart menjelaskan secara rinci semua suka dan duka yang dia alami di industri ini.
Ia mengatakan bahwa ide utama yang diinginkannya adalah agar pembaca merasa seolah-olah sedang membaca sebuah cerita dan bukan sekadar biografi.

Natalia Neidhart menghadiri Build Series untuk membahas “Total Divas” di Build Studio pada 25 Oktober 2017 di New York City. (Fotografi Steve Zack/Sihir Film)
Kejuaraan Kelas Berat Dunia WWE dibatalkan karena cederanya Seth Rollins, pertandingan perebutan gelar antara bintang-bintang top
“Gulat adalah latar belakang cerita saya, namun buku ini menceritakan tentang pertandingan yang saya jalani atau bagaimana saya memulainya,” katanya. “Orang-orang yang membacanya, mereka tidak sabar untuk melanjutkan ke bab berikutnya karena ini adalah sebuah cerita. Mereka tidak sabar untuk mengetahui apa yang akan terjadi dalam cerita tersebut dan itu adalah cerita yang tidak diketahui orang-orang.”
Dalam satu contoh, Neidhart menulis tentang mengingat kembali perasaan seperti “yang terakhir tersisa” dari keluarganya dalam bisnis gulat profesional.
Tekanan tentu ada sepanjang karier Neidhart.
“Saya pikir ini hanya soal mencintai apa yang saya lakukan,” katanya kepada Fox News Digital. “Sulit dipercaya saya sudah berada di WWE selama hampir dua dekade, namun saya benar-benar menyukai apa yang saya lakukan. Sama seperti apa pun, akan ada hal-hal yang Anda sukai, akan ada hal-hal yang sulit, dan akan ada hal-hal yang menantang, namun tidak ada perasaan yang lebih hebat daripada berjalan melewati tirai melakukan sesuatu yang Anda sukai dan merasa senang karenanya.”
“Saya pikir hal yang paling penting bagi keluarga saya adalah keluarga saya telah melakukan banyak hal di industri ini, namun pada akhirnya, kami semua memiliki kesempatan untuk terjun ke industri ini untuk benar-benar mewujudkan impian kami, dan ini merupakan hal yang luar biasa.”
“The Last Hart Beating: From the Dungeon to WWE” akan dirilis pada hari Selasa.
Dia mengungkapkan harapannya agar para penggemar dapat “menyembuhkan” dengan membaca buku dan mempelajari pengalamannya.

Pegulat WWE Natalya Neidhart memegang sabuk juaranya di Build Studio pada 25 Oktober 2017 di New York City. (Astrid Stawiarz/Getty Images)
Klik di sini untuk mengunduh aplikasi FOX NEWS
“Jika pesan dalam buku saya dapat dijadikan acuan, jika ada yang mendapatkan sesuatu dari buku ini, saya harap ini dapat membantu mereka untuk sembuh,” katanya. “Anda dapat membaca buku saya tanpa mengetahui apa pun tentang gulat dan Anda akan sepenuhnya memahaminya.
“Dan itu adalah hal yang besar bagi saya — saya ingin menulis sebuah buku yang mudah dibaca dan Anda bisa menyukai gulat, Anda bisa membenci gulat, Anda tidak tahu apa-apa tentang gulat, dan Anda bisa sepenuhnya memahami buku itu karena ini tentang manusia dan hubungan, dan menurut saya buku itu akan menyembuhkan banyak orang.”
Ikuti Fox News Digital Liputan olahraga di X Dan berlangganan Buletin Huddle Olahraga Fox News.
Berita
Permainan perdagangan agen PayPal menunjukkan mengapa fleksibilitas, bukan standar, yang akan menentukan gelombang e-commerce berikutnya

Sementara bisnis yang ingin menjual barang dan jasa secara online menunggu Tulang punggung perdagangan agen untuk dibagi, PayPal Mereka berharap fitur-fitur barunya akan mengisi kesenjangan tersebut.
Perusahaan pembayaran ini meluncurkan solusi yang dapat ditemukan yang memungkinkan organisasi membuat produk mereka tersedia di platform obrolan apa pun, terlepas dari model atau protokol pembayaran agen.
PayPal, peserta Google‘S Protokol Pembayaran Agen (AP2)menemukan bahwa mereka dapat memanfaatkan hubungan mereka dengan pedagang dan institusi untuk membantu membuka jalan bagi transisi yang lebih mudah ke perdagangan agen dan menawarkan fleksibilitas yang mereka pelajari akan bermanfaat bagi ekosistem.
Belanja yang didukung AI akan terus berkembang, sehingga bisnis dan merek harus mulai meletakkan dasar sejak dini, kata Michelle Gill, manajer umum bisnis kecil dan layanan keuangan di PayPal, kepada VentureBeat.
“Kami pikir pedagang yang secara historis berjualan melalui toko web, khususnya di e-commerce, akan sangat membutuhkan cara untuk aktif dalam semua model bahasa besar ini,” kata Gill. “Tantangannya adalah tidak ada seorang pun yang benar-benar tahu seberapa cepat semua ini akan bergerak. Masalah yang kami coba bantu pikirkan adalah bagaimana melakukan semua ini dengan sentuhan sesedikit mungkin sambil menggunakan infrastruktur yang sudah Anda miliki tanpa integrasi besar.”
Dia menambahkan bahwa berbelanja dengan AI juga akan menyebabkan “kembalinya konsumen yang mencoba memastikan investasi mereka terlindungi.”
PayPal telah bermitra dengan pembuat situs web Minggu, Simbiodan perdagangan Alat belanja Untuk membawa produk ke platform obrolan seperti Kebingungan.
Belanja yang didukung agen
Layanan perdagangan proxy PayPal mencakup dua fitur. Yang pertama adalah Agent Ready, yang memungkinkan pedagang PayPal yang ada menerima pembayaran pada platform AI. Yang kedua disebut Shop Sync, yang memungkinkan data produk perusahaan ditemukan melalui berbagai antarmuka obrolan bertenaga AI. Dibutuhkan informasi katalog perusahaan dan mengirimkan data inventaris dan pemenuhan ke platform obrolan.
Data tersebut disimpan di gudang pusat tempat model AI dapat menyerap informasi tersebut, kata Gill.
Untuk saat ini, bisnis dapat mengakses sinkronisasi toko dengan Agent Ready yang akan hadir pada tahun 2026.
Agentic Commerce Services adalah solusi satu-ke-banyak, dan itu akan berguna saat ini, di mana MBA yang berbeda menggabungkan sumber data yang berbeda untuk menampilkan informasi, kata Gill.
Manfaat lainnya meliputi:
Integrasi cepat dengan mitra saat ini dan masa depan
Lebih banyak penemuan produk melalui pengalaman penelusuran tradisional, penjelajahan, dan keranjang belanja
Pertahankan wawasan dan hubungan pelanggan seiring merek terus mengontrol catatan dan komunikasi mereka dengan pelanggan.
Untuk saat ini, layanan ini hanya tersedia melalui Perplexity, namun Gill mengatakan lebih banyak platform akan segera ditambahkan.
Platform AI yang terfragmentasi
Perdagangan proksi masih dalam tahap awal. Agen AI mulai menjadi lebih baik dalam membaca browser. Meskipun platform seperti ChatGPT, Gemini, dan Perplexity kini dapat menawarkan produk dan layanan berdasarkan permintaan pengguna, orang belum dapat membeli sesuatu dari obrolan.
Saat ini terdapat perlombaan untuk menciptakan standar yang memungkinkan agen bertransaksi atas nama pengguna dan membayar barang. Berbeda dengan AP2 Google, OpenAI Dan tape Anda punya Protokol Perdagangan Proksi (ACP) Dan Visa Saya memecatnya Protokol Proksi Tepercaya.
Selain memungkinkan lapisan kepercayaan bagi agen untuk melakukan transaksi, masalah lain yang dihadapi organisasi dalam perdagangan agen adalah fragmentasi. Platform obrolan yang berbeda menggunakan model berbeda yang juga menafsirkan informasi dengan cara yang sedikit berbeda. PayPal telah belajar bahwa ketika bekerja dengan pedagang, fleksibilitas itu penting, kata Gill.
“Bagaimana Anda memutuskan apakah akan menghabiskan waktu Anda untuk berintegrasi dengan Google atau Microsoft atau ChatGPT atau Perplexity? Dan masing-masing dari mereka sekarang memiliki protokol yang berbeda, katalog yang berbeda, pengaturan yang berbeda, segalanya yang berbeda. Dibutuhkan banyak waktu untuk menentukan di mana Anda harus menghabiskan waktu Anda,” kata Gill.

baruAnda sekarang dapat mendengarkan artikel Fox News!
Raksasa yang tertidur itu akhirnya terbangun pada Senin larut malam di Pantai Barat dan Selasa dini hari di Pantai Timur.
Freddie Freeman mencapai posisi terbawah pada inning ke-18 dan melakukan home run solo untuk memberi Los Angeles Dodgers kemenangan Seri Dunia Game 3 atas Toronto Blue Jays, 6-5. Dia menjadi pemain pertama dalam sejarah MLB Postseason yang mencapai beberapa home run di Seri Dunia. Dia melakukannya pada pertandingan pertama tahun lalu melawan New York Yankees.
KLIK DI SINI UNTUK CAKUPAN OLAHRAGA LEBIH LANJUT DI FOXNEWS.COM
Freddie Freeman dari Los Angeles Dodgers merayakan home run melawan Toronto Blue Jays pada inning ke-18 di Game 3 Seri Dunia, Senin, 27 Oktober 2025, di Los Angeles. (Foto AP/Brynn Anderson)
Maraton bisa saja berakhir kapan saja antara inning ke-10 dan ke-18. Dodgers memiliki peluang besar di posisi terbawah ke-13. Freeman datang untuk memukul dengan pangkalan terisi dan memukul bola sejauh yang dia bisa sebelum pemain luar Blue Jays melacaknya.
Toronto membuat beberapa keputusan berisiko di jalur dasar menjelang pertandingan. Upaya yang dilakukan saat itu tidak sia-sia dan menutup permainan, namun permainan bertahan dari Tommy Edman dan Teoscar Hernandez mampu memadamkan harapan kemenangan Blue Jays.
Pertandingan mungkin tidak akan menghasilkan babak tambahan tanpa permainan Shohei Ohtani.
Ohtani mencetak dua home run dalam malam 4-untuk-4 untuk Dodgers. Dia mencapai pangkalan dengan selamat sembilan kali, membuat rekor Seri Dunia. Ohtani dijadwalkan untuk bermain di Game 4 pada Selasa malam — kurang dari 24 jam setelah home run Freeman.
“Saya ingin tidur secepat mungkin agar saya bisa bersiap-siap,” kata Ohtani kepada Tom Verducci dari FOX melalui seorang penerjemah.

Shohei Ohtani dari Los Angeles Dodgers merayakan home run melawan Toronto Blue Jays pada inning ketujuh di Game 3 Seri Dunia, Senin, 27 Oktober 2025, di Los Angeles. (Foto AP/Brynn Anderson)
MOOKIE BETTS DODGERS memenangkan Penghargaan Kemanusiaan Roberto Clemente
Pereda Dodgers Will Klein memainkan peran besar dalam kemenangan Los Angeles. Klein melakukan empat inning bisbol tanpa gol dan melakukan lima inning. Dia melempar 72 lemparan — terbanyak kedua sepanjang malam di belakang rookie Tyler Glasnow.
Hernandez memulai Los Angeles dengan home run solo shortstop Blue Jays Max Scherzer di inning kedua. Ohtani melanjutkannya dengan home run pertamanya malam itu di inning ketiga. Tapi hanya ini dua kelemahan Scherzer.
Pelempar bintang veteran mengunci rekor home run. Dia dipukul untuk tiga perolehan run pada lima pukulan dalam 4,1 inning.
Toronto kembali berada di puncak posisi keempat.
Penangkap Blue Jays, Alejandro Kirk, melakukan home run tiga kali dari Tyler Glasnow untuk memberi Toronto keunggulan. Vladimir Guerrero Jr. dan Bo Bichette mencetak gol di ruang bawah tanah. Kemudian, Andres Jimenez mencetak gol Addison Barger dengan pengorbanan.

Alejandro Kirk dari Toronto Blue Jays merayakannya setelah melakukan home run tiga kali melawan Los Angeles Dodgers pada inning keempat di Game 3 Seri Dunia, Senin, 27 Oktober 2025, di Los Angeles. (Foto AP/David J. Phillip)
Ganda RBI Ohtani dan single RBI Freddie Freeman menyamakan permainan di posisi terbawah kelima. Tapi Bichette memilih Guerrero dalam home run untuk kembali memimpin.
Tentu saja, Ohtani mempunyai peluang untuk memberikan dampak yang lebih besar. Dengan tidak ada seorang pun yang tersingkir di posisi terbawah ketujuh, Ohtani melakukan pukulan keras dari Ceranthony Dominguez untuk menyamakan kedudukan lagi.
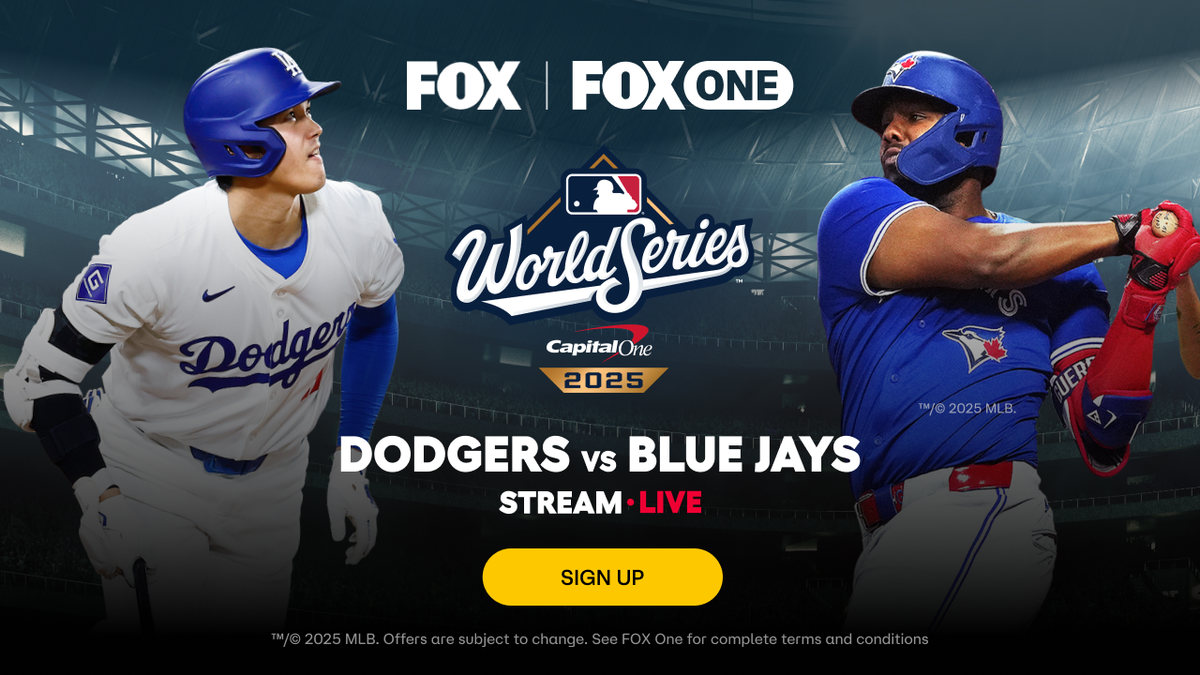
Los Angeles Dodgers dan Toronto Blue Jays bertemu di Seri Dunia 2025. (rubah)
Klik di sini untuk mengunduh aplikasi FOX NEWS
Itu adalah maraton 18 inning dari sana, menyamai rekor permainan terpanjang dalam sejarah Seri Dunia.
Game 4 dijadwalkan untuk Selasa malam pukul 8 malam ET di FOX.
Ikuti Fox News Digital Liputan olahraga di X Dan berlangganan Buletin Huddle Olahraga Fox News.

 Berita8 tahun ago
Berita8 tahun agoThese ’90s fashion trends are making a comeback in 2017
- Berita8 tahun ago
The final 6 ‘Game of Thrones’ episodes might feel like a full season
- Berita8 tahun ago
According to Dior Couture, this taboo fashion accessory is back
- Berita8 tahun ago
Uber and Lyft are finally available in all of New York State
- Berita8 tahun ago
The old and New Edition cast comes together to perform

 Bisnis9 bulan ago
Bisnis9 bulan agoMeta Sensoren Disensi Internal atas Ban Trump Mark Zuckerberg
- Berita8 tahun ago
Phillies’ Aaron Altherr makes mind-boggling barehanded play
- Berita8 tahun ago
New Season 8 Walking Dead trailer flashes forward in time


