
Berita
Terdakwa Polisi Ibukota Mengubah Data Kejahatan Sebelum Trump Federal

baruAnda sekarang dapat mendengarkan Fox News!
Beberapa minggu sebelum Presiden Donald Trump memotret Washington, DC dan kepolisian karena masalah kejahatan, administrasi kepolisian ibukota dituduh melakukan statistik kejahatan untuk mencapai hasil yang lebih menguntungkan.
“Ketika anggota kami menanggapi tempat kejahatan kejahatan di mana ada korban laporan kejahatan, pasti akan ada seorang letnan atau pemimpin yang akan muncul dalam adegan ini dan mengarahkan anggota -anggota ini untuk mengambil laporan tentang kejahatan yang kurang.”
“Jadi, alih -alih mengambil api, menikam atau menghancurkan laporan, mereka akan meminta petugas ini untuk mengambil laporan tentang pencurian atau orang yang terluka ke rumah sakit atau serangan kejahatan, yang bukan jenis klasifikasi yang sama.”
Tuduhan Presiden Federasi mengikuti komentar Washington, DC, Kepala Polisi Michael Polim pada pertengahan Mei, diduga mengubah statistik kejahatan di daerahnya, media setempat melaporkan pada bulan Juli.
Kekerasan telah tumbuh lebih mematikan, meskipun Demokrat mengklaim level terendah dalam 30 tahun
Kantor Polisi Metropolitan di Washington, DC, dituduh mengubah statistik kejahatan. (Gambar Getty)
Kepala polisi dituduh memalsukan data kejahatan untuk membuat tren kejahatan tampaknya lebih cocok untuk kota, tetapi ia membantah tuduhan ini. Seminggu sebelum penangguhannya, Polim mengajukan pengaduan peluang kerja yang sama terhadap outlet lokal yang lebih tinggi NBC Washington Saya sebutkan.
Pulliam saat ini sedang diselidiki pada dugaan statistik variabel. Departemen Kepolisian Metropolitan Fox News mengatakan kepada Digital pada hari Kamis ketika dia memintanya untuk berkomentar dan pembaruan tambahan tentang kasus ini, bahwa itu “tidak mengomentari penyelidikan internal atau masalah karyawan.”
Mantan Kepala Polisi Capitol mengatakan bahwa kejahatan “geng pemuda” di ibukota telah meningkat, dan melarikan diri dari “lingkungan tertentu”
Tuduhan tentang mengubah statistik kejahatan Trump di administrasi kepolisian segera diikuti sebagai tanggapan atas serangkaian pembunuhan dan serangan terkemuka, di samping gelombang kejahatan di daerah yang berlangsung sejak sore tahun 2020.

Presiden Donald Trump berbicara kepada pers tentang publikasi agen penegak hukum federal di Washington, DC, 11 Agustus 2025. (Reuters/Jonathan Ernest)
Trump mengatakan pada hari Senin: “Ibukota kami telah melampaui geng -geng kekerasan, penjahat darah -hta, dan gerombolan pemuda liar, dan narkoba serta anestesi dan para tunawisma.” “Kami tidak akan membiarkan itu terjadi lagi. Kami tidak akan menerimanya.”
“Kami mengembalikannya di bawah wewenang yang dibahas sebagai Presiden Amerika Serikat, saya secara resmi menyebut Pasal 740 Hukum Provinsi Kolombia,” tambahnya. “Anda tahu apa itu. Dan Departemen Kepolisian Modal meletakkan modal di bawah kendali federal langsung … Selain itu, saya menerbitkan Pengawal Nasional untuk membantu membangun kembali hukum, ketertiban, dan keselamatan publik di dalam Washington, DC Mereka akan diizinkan melakukan pekerjaan mereka dengan benar. “
Pada hari Kamis, Trump menentang data kejahatan yang merusak tuduhan di daerah tersebut.
“Mereka sekarang sedang menyelidiki,” kata Trump pada hari Kamis di konferensi pers untuk Oval Office. “Mereka memberikan kejahatan palsu ini sama seperti mereka memberikan statistik lain di dunia keuangan. Tetapi mereka adalah statistik palsu. Washington, DC, berada pada titik terburuknya, dan Anda akan segera berada pada titik terbaiknya. Anda akan menjadi sangat aman, Anda akan mendapatkan kota bebas kejahatan.”
Fox Digital Fox Digital Foundation Fost Digital Foundation First Legal Foundation, yang didirikan oleh penasihat Gedung Putih Stephen Miller, “Fox Digital Foundation”, yang didirikan oleh penasihat Gedung Putih Stephen Miller, mendirikan permintaan untuk mendapatkan catatan kejahatan dan data yang dikumpulkan oleh Departemen Kepolisian Modal yang dikumpulkan, termasuk catatan apa pun “mencerminkan kemakmuran atau penyebaran” data kejahatan dan statistik.
“Radikalis” para pejabat ibukota memperlakukan petugas “seperti kebodohan,” kata pemimpin polisi.
Anggota parlemen Demokrat dan pemimpin liberal lokal telah mengkritik Trump pada kota federal-yang termasuk ratusan anggota penjaga nasional yang membanjiri ibukota, serta staf penegak hukum dari lembaga-lembaga seperti FBI, Administrasi Penegakan Narkoba, Polisi Capitol Amerika dan Kantor Tobak, senjata api, dan interpretasi yang membantu dengan undang-undang Trump yang berkuasa.

Petugas polisi mendirikan pos pemeriksaan pinggir jalan di 14th Street Northwest pada 13 Agustus 2025, di Washington, setelah kepolisian ibukota. (Tasos Katopodis/Getty Images)
“Kejahatan kekerasan di Washington, DC, berada pada level terendah dalam 30 tahun,” kata komandan minoritas di Dewan Perwakilan Rakyat, Gubernur Jeffrey, Dean. Alai pada hari Senin. “Donald Trump tidak memiliki dasar untuk mengendalikan administrasi kepolisian setempat. Safar dapat dipercaya tentang masalah hukum dan ketertiban.”
Saat mendengarkan Trump tidak tertarik, ia mencoba membenarkan penyebaran Garda Nasional di ibukota, inilah kebenarannya: Kejahatan kekerasan Di ibukota di level terendah dalam 30 tahun, “mantan menteri luar negeri Hillary Clinton diterbitkan ke x.
Washington, ibukota, termasuk di antara kota-kota di mana kejahatan nasional dimakamkan pada tahun 2020-ketika pandemi Covid-19 meletus dan protes serta kerusuhan diliputi di seluruh catatan negara-1988. Kejahatan Pembunuhan Tahun ItuYang merupakan level tertinggi di kota selama 16 tahun. Pembunuhan melonjak menjadi 226 pada tahun 2021, menurun menjadi 203 pada tahun 2022 dan naik pada tahun 2023 menjadi 274-tinggi dari 20 tahun.
Trump mengklaim kejahatan ibukota, statistik dari kota -kota yang kejam dan terkenal di seluruh dunia
DC menyaksikan bahwa pembunuhan menurun sekitar 31 % dari tahun 2023 hingga 2024, menurut data Administrasi Kepolisian Metropolitan pada akhir tahun, yaitu 187 pada tahun 2024. Data menunjukkan bahwa kejahatan kekerasan di semua bidang menurun sekitar 35 % dari tahun 2023, ketika administrasi melaporkan 5345 aksiden, menjadi 2024, ketika itu disebutkan 3.4.
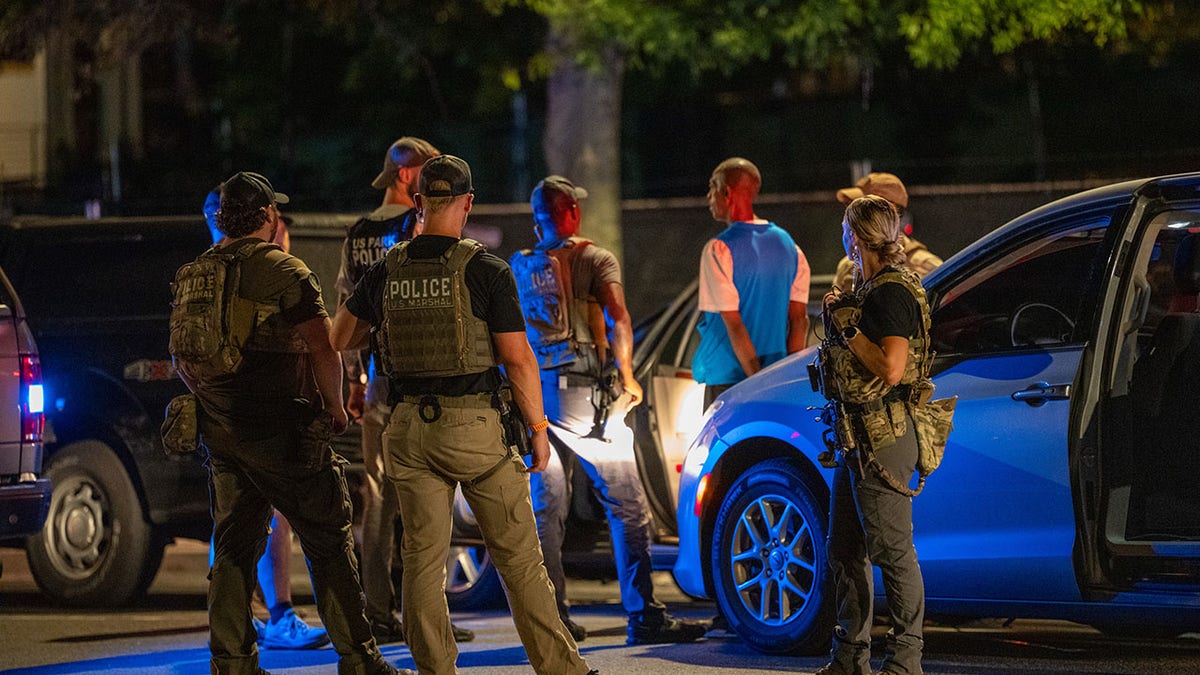
Pejabat penegak hukum ditangkap setelah menambahkan karakter federal Presiden Trump ke kota. (Gambar Andrew Leyden/Getty)
Sebuah studi yang diterbitkan oleh Dewan Peradilan Pidana pada bulan Juli menemukan bahwa peluang seseorang yang menghadapi kejahatan kekerasan di Washington, DC, telah menurun dalam beberapa tahun terakhir, tetapi kemungkinan kematian selama kejahatan semacam itu telah meningkat.
Studi ini mempelajari data kejahatan kekerasan dari 17 kota besar di Amerika Serikat antara 2018 dan 2024, khususnya penyelidikan atas kematian kejahatan kekerasan di kota -kota tersebut. Washington, DC, menemukan tingkat pembunuhan tertinggi dalam kelompok – yang termasuk Baltimore dan Chicago – peningkatan 38 % pada gadis itu pada tahun 2024 dibandingkan dengan 2018.
Secara Eksklusif: Kelompok Hukum yang Meminta Penyelarasan Permintaan Trump untuk Meminta Data Kejahatan Kejahatan, mengutip dugaan manipulasi
Studi ini menemukan bahwa gadis di ibukota melonjak sebesar 341 % besar jika dibandingkan dengan data 2012, dan penelitian ini menginformasikan bahwa ada 13 pembunuhan per 1.000 kejahatan kekerasan pada 2012 hingga 57 pembunuhan per 1.000 kejahatan kekerasan pada tahun 2024.
Studi ini mengidentifikasi gadis itu sebagai “jumlah pembunuhan untuk semua serangan dan pencurian yang ketat.”

Presiden Donald Trump mengumumkan federasi di Kepolisian Washington pada 11 Agustus 2025. (Getty)
“Anda memiliki peluang lebih rendah dari korban, tetapi jika Anda adalah korban, Anda memiliki kesempatan yang lebih besar untuk mati,” kata dosen John Jelian Snyder, seorang pensiunan petugas polisi New York, mengatakan kepada Fox News pada hari Selasa tentang tren kejahatan kekerasan di ibukota negara itu.
Fox News Senin, kepala Fox News Senin, mengatakan kepada ekspresi federal Trump sambil mengkritik kejahatan kota.
Klik di sini untuk mendapatkan aplikasi Fox News
“Kami sepenuhnya setuju dengan presiden di sini bahwa kejahatan di provinsi itu luar. Wawancara dengan Fox Business. “Konsep ini adalah bahwa kejahatan sebenarnya telah mengurangi piala lama. Mereka menggunakan statistik dengan cara yang membuat kejahatan berkurang, tetapi petugas pengaturan kami tahu bahwa kami akan meminta kontak, untuk pencurian bersenjata, luka tusuk, pencurian, penembakan, kejahatan mati, dan kejahatan tidak pergi ke mana pun.”
Fox News Digital telah berkomunikasi dengan Federasi untuk komentar tambahan tentang masalah ini, tetapi dia tidak segera menerima tanggapan.
Hana Bannerk dari Fox News Digif dan Brin Depsh berkontribusi pada laporan ini.

Ingin lebih banyak visi yang cerdas dari kotak masuk Anda? Berlangganan buletin mingguan kami untuk mendapatkan apa yang hanya terkait dengan lembaga AI, data dan pemimpin keamanan. Berlangganan sekarang
Peneliti dari University of California, BerkeleyDan Universitas Stanford Dan Databricks Saya telah menyajikan cara baru untuk meningkatkan kecerdasan buatan yang disebut terobosan Ini sangat mengungguli teknik pembelajaran penguatan tradisional (RL) untuk mengadaptasi model bahasa besar (LLM) untuk tugas -tugas khusus.
GEPA menghilangkan model populer untuk belajar melalui ribuan upaya untuk bereksperimen dan kesalahan yang dipandu oleh nilai numerik sederhana. Sebaliknya, pemahaman bahasa LLM digunakan untuk memikirkan kinerjanya, mendiagnosis kesalahan dan mengembangkan instruksinya. Selain lebih akurat daripada di tempat, GEPA secara signifikan lebih efisien, mencapai hasil super dengan kurang dari 35 kali.
Untuk perusahaan yang membangun agen dan biografi kerja yang kompleks, ini diterjemahkan langsung ke dalam kursus pengembangan yang lebih cepat, biaya matematika yang jauh lebih rendah, dan aplikasi yang lebih andal.
Biaya tinggi untuk meningkatkan sistem kecerdasan buatan modern
Aplikasi AI untuk lembaga modern jarang satu panggilan ke LLM. Seringkali “Sistem AI Kendaraan”, alur kerja kompleks yang melakukan beberapa seri LLM, alat eksternal seperti basis data atau penerjemah yang diterjemahkan dalam instruksi perangkat lunak, dan logika untuk melakukan tugas -tugas lanjutan, termasuk penelitian multi -step dan analisis data.
Kecerdasan buatan membatasi batasnya
Tutup daya, biaya tinggi simbol, dan penundaan dibentuk kembali. Bergabunglah dengan salon eksklusif kami untuk menemukan bagaimana perbedaan besar:
- Mengubah energi menjadi keuntungan strategis
- Mengajar penalaran yang efektif untuk keuntungan produktivitas nyata
- Membuka Pengembalian Investasi Kompetitif dengan Sistem Kecerdasan Buatan Berkelanjutan
Mengamankan tempat Anda untuk tinggal di latar depan: https://bit.ly/4mwngngo
Ada cara umum untuk meningkatkan sistem ini adalah melalui metode pembelajaran penguatanSeperti kebijakan relatif grup (GRPO), teknik yang digunakan dalam model pemikiran umum, termasuk Deepsek-R1. Metode ini diperlakukan sebagai kotak hitam; Ini menjalankan tugas, mendapatkan skala sukses sederhana (“hadiah standar”, seperti 7/10 derajat), dan menggunakan komentar ini untuk secara perlahan mendorong parameter model ke arah yang benar.
Kerugian utama RL adalah inefisiensi sampel. Untuk belajar secara efektif dari gelar numerik yang terpisah ini, metode RL sering membutuhkan puluhan ribu, atau bahkan ratusan ribu, dari percobaan, yang dikenal sebagai “pengguliran”. Untuk aplikasi lembaga apa pun di dunia nyata yang mencakup panggilan alat mahal (misalnya, informasi API, perakitan kode) atau menggunakan model kepemilikan yang kuat, proses ini lambat dan mahal.
Seperti yang diceritakan kepada Lakshya A Agrawal, rekan penulis kertas dan mahasiswa PhD di University of California, Berkeley, VentureBeat, kompleksitas ini merupakan hambatan besar bagi banyak perusahaan. Agrouwal mengatakan: “Untuk banyak perbedaan, RL tidak praktis karena pendekatan biaya dan kompleksitasnya sejauh ini adalah rekayasa tangan yang cepat.” Dia menunjukkan bahwa GEPA dirancang untuk tim yang perlu meningkatkan sistem yang dibangun pada model atas yang tidak dapat sering dikendalikan, memungkinkan mereka untuk meningkatkan kinerja tanpa mengelola grup GPU khusus.
Para peneliti membingkai tantangan ini sebagai berikut: “Bagaimana kita dapat mengekstraksi sinyal pembelajaran maksimum dari setiap penawaran mahal untuk memungkinkan adaptasi efektif sistem kecerdasan buatan yang canggih dalam pengaturan yang rendah atau anggaran?”
Belajar dengan baik dalam bahasa
GEPA (Genetic-Pareto) adalah peningkatan cepat yang menangani tantangan ini dengan mengganti imbalan sporadis dengan komentar bahasa yang kaya dan alami. Ini meningkatkan fakta bahwa implementasi penuh dari sistem kecerdasan buatan (termasuk langkah -langkah pemikiran, panggilan alat, dan bahkan pesan kesalahan) dapat diurutkan dalam teks yang dapat dibaca dan dipahami oleh LLM. Metodologi GEPA didasarkan pada tiga kolom dasar.
Yang pertama adalah “pengembangan terarah genetik”, di mana GEPA memperlakukan serangkaian klaim seperti gen. Ini “berbalik” berulang kali untuk membuat versi baru yang lebih baik. Mutasi ini adalah proses pintar yang didorong oleh kolom kedua: “Refleksi dengan reaksi linguistik alami.” Setelah beberapa operan, GEPA LLM memberikan implementasi penuh (apa yang coba dilakukan oleh sistem) dan hasilnya (apa yang terjadi dengan benar atau salah). Kemudian “LLM” mencerminkan komentar ini dalam bahasa alami untuk mendiagnosis masalah dan menulis gelombang yang lebih baik dan lebih rinci. Misalnya, alih -alih hanya melihat tingkat rendah dalam misi pembuatan kode, itu dapat menganalisis kesalahan dalam kode dan menyimpulkan klaim untuk menentukan penerbitan perpustakaan tertentu.
Kolom ketiga adalah “Pilihan Berbasis Parito”, yang menjamin eksplorasi cerdas. Alih -alih hanya berfokus pada router yang berkinerja terbaik, yang dapat menyebabkan tersandung dalam solusi optimal (optimal lokal “, GEPA mempertahankan berbagai klaim” khusus “. Ini melacak apa yang menuntut kinerja yang lebih baik pada berbagai contoh individu, dan membuat daftar yang lebih baik. Dengan mengambil solusi yang lebih baik. Dengan mengambil sampel dari berbagai koleksi strategi kemenangan ini, Gepa jaminan yang membuat ini menjamin bahwa GEPA itu menjamin hal itu. input.

Efektivitas seluruh proses ini tergantung pada apa yang oleh peneliti disebut “rekayasa pengaliran counter”. Agrawal menjelaskan bahwa kuncinya adalah permukaan rincian teks yang kaya yang sudah diproduksi oleh sistem tetapi sering diabaikan. Dia mengatakan: “Jalur saluran tradisional sering mengurangi detail ini menjadi satu hadiah numerik, yang menghalangi penyebab hasil tertentu.” “Arah penting GEPA adalah untuk mengatur reaksi yang hanya memperluas hasil tetapi juga jalur dan kesalahan medium dalam teks normal – bukti yang sama yang digunakan seseorang untuk mendiagnosis perilaku sistem.”
Misalnya, untuk sistem pengambilan dokumen, ini berarti memasukkan dalam dokumen daftar yang dipulihkan dan dilewatkan dengan benar, alih -alih menghitung hasil akhir.
Gepa di tempat kerja
Para peneliti mengevaluasi GEPA di empat tugas yang beragam, termasuk jawaban atas hotpotqa dan informasi yang mempertahankan privasi (pupa). Mereka menggunakan kedua model open source (QWEN3 8B), kepemilikan (GPT-4.1 Mini), dan perbandingan GEPA dengan GRPO berbasis RL dan peningkatan klaim MIPROV2 modern.
Di semua tugas, GEPA telah sangat mengungguli GRPO, mencapai tingkat tinggi hingga 19 % dengan penggunaan hingga 35 kali. Dia menjelaskan bahwa Agrawal memberikan contoh nyata dari gain efisiensi ini: “Kami menggunakan GEPA untuk meningkatkan sistem QA dalam waktu sekitar 3 jam melawan 24 jam GRPO – penurunan 8x pada saat pengembangan, dengan kinerja 20 % lebih tinggi juga.” “Biaya peningkatan berbasis RL untuk skenario yang sama dalam tes kami adalah sekitar $ 300 pada saat GPU, sementara GEPA harganya kurang dari $ 20 untuk hasil yang lebih baik-15x penghematan dalam pengalaman kami.”

Selain kinerja mentah, para peneliti menemukan bahwa sistem GEPA yang lebih baik lebih dapat diandalkan ketika menghadapi data yang tidak terlihat baru. Ini diukur dengan “celah melingkar” (perbedaan antara kinerja dalam data pelatihan dan data uji akhir). Agrawal mengasumsikan bahwa ini karena GEPA belajar dari reaksi terkaya. Dia mengatakan: “Kesenjangan generalisasi yang lebih kecil di GEPA mungkin berasal dari penggunaan reaksi yang kaya dalam bahasa alami di setiap hasil yang telah berhasil, dan apa yang gagal, dan mengapa-dari hanya mengandalkan bonus numerik.” “Sistem ini dapat mendorong pengembangan instruksi dan strategi berdasarkan pemahaman yang lebih luas tentang keberhasilan, bukan hanya pola belajar untuk data pelatihan.” Untuk institusi, keandalan yang ditingkatkan ini berarti aplikasi kecerdasan buatan yang kurang rapuh dan lebih mudah beradaptasi dengan peran yang dihadapi pelanggan.
Salah satu manfaat praktis utama adalah bahwa klaim GEPA berdasarkan instruksi hingga 9,2 kali klaim optimal seperti MIPROV2, yang mencakup banyak contoh yang lebih sedikit. Klaim Luxor mengurangi waktu kedatangan dan mengurangi biaya model API. Ini membuat aplikasi akhir lebih cepat dan lebih murah untuk dijalankan dalam produksi.
Makalah ini juga memberikan hasil yang menjanjikan untuk penggunaan GEPA sebagai strategi penelitian “waktu penalaran”, yang mengubah kecerdasan buatan dari satu generator yang menjawab untuk memecahkan masalah berulang. Agrawal adalah skenario di mana GEPA dapat digabungkan ke dalam pipa CI/CD perusahaan. Ketika kode baru dilakukan, GEPA dapat membuat beberapa versi yang ditingkatkan dan secara otomatis memperbaikinya, mengujinya untuk kinerja, buka permintaan penarikan dengan variabel kinerja terbaik untuk insinyur untuk ditinjau. “Ini mengubah peningkatan menjadi proses yang berkelanjutan dan mekanis-generasi solusi yang sering bertepatan atau melebihi penyempurnaan ahli manual,” kata Agrawal. Dalam pengalaman mereka untuk menghasilkan CUDA, pendekatan ini telah memperkuat 20 % dari tugas ke tingkat ahli, dibandingkan dengan 0 % untuk mencoba satu bidikan GPT-4O.
Para penulis makalah percaya bahwa GEPA adalah langkah penting menuju model baru untuk mengembangkan kecerdasan buatan. Tetapi selain menciptakan lebih banyak kecerdasan buatan, efeknya yang paling mendesak pada mereka yang mendapatkan sistem kinerja tinggi mungkin.
“Kami berharap GEPA memungkinkan transformasi positif dalam membangun sistem kecerdasan buatan-yang membuat peningkatan sistem yang dapat dilakukan oleh pengguna akhir, yang sering memiliki pengalaman lapangan terkait tugas, tetapi tidak harus waktu dan kemauan untuk mempelajari rincian RL yang kompleks,” kata Agrawal. “Ini memberi energi langsung kepada para pemangku kepentingan dengan pengetahuan bidang tugas tertentu.”

Tautan sumber
Berita
Kepala Kepolisian Seattle dikatakan makan di dekatnya sambil mencuri perhiasan untuk dua juta dolar

baruAnda sekarang dapat mendengarkan Fox News!
Menurut apa yang dilaporkan, kepala Departemen Kepolisian Seattle jauh dari toko perhiasan ketika ia dipindahkan di siang hari bolong pada hari Kamis, ketika pencuri keluar dengan perkiraan jumlah berlian $ 2 juta, emas dan kebanggaan.
Pada hari itu, empat pencuri yang meyakinkan melakukan pencurian dalam perhiasan Menashe & Sons di Seattle Barat, mengancam karyawan dengan penyemprotan beruang dan senapan Thunderbolt setelah memecahkan pintu depan kaca yang tertutup dengan palu dan mencuri segala sesuatu dari enam kotak lebar di toko.
Tetapi dengan pencurian perhiasan, kepala polisi Seattle Ceann Barnes akan pergi yogurt. Jason Rantz Penawaran di Seattle Reed 770 AM.
Seorang juru bicara Departemen Kepolisian Seattle dikonfirmasi Jason Rantz Dia menunjukkan bahwa presiden sudah dekat, tetapi dia tidak bisa mengatakan dengan tepat di mana itu adalah waktu pencurian.
Pencuri yang malang menarik pencurian tengah hari di toko perhiasan Seattle dalam waktu kurang dari dua menit
Empat pencuri persuasif menyiapkan perampokan kasar di toko perhiasan di Seattle Barat, meninggalkan berlian dan jam tangan emas dan mewah dalam waktu kurang dari dua menit. (Menashe Sons & Jeweles)
“Dia adalah presiden Barnes dan rincian keamanannya di perusahaan terdekat ketika pencurian itu terjadi,” kata juru bicara itu. “Mereka berada di dalam pekerjaan dan tidak mengetahui kejahatan yang terungkap.
Juru bicara itu menambahkan: “Para tersangka ada di dalam dan di luar toko perhiasan dalam 90 detik.” “Detail keamanannya berada dalam pakaian yang jelas pada saat pencurian.”
Juru bicara departemen juga mengatakan Penawaran Radio Presiden dan rinciannya menjadi sadar akan pencurian setelah kendaraan polisi menanggapi lampu dan peringatan ke tempat kejadian.
Polisi California NAB 7 Warga Negara Asing Dalam Mencuri Toko Perhiasan, 1 Tersangka masih longgar

Kepala Kepolisian Seattle of Seattle Parins dikatakan makan siang di sebuah restoran, Yarawat, Yaradat, ketika permata itu dicuri. (Menashe Sons & Jeweles)
Polisi mengatakan pencuri membuka kasus dengan kalung zamrud senilai $ 125.000 dan sebuah kasus yang berisi sekitar 750.000 dolar jam Rolex.
“Kami terguncang sebagai karyawan,” kata Josh Minash, wakil kepala keluarga keluarga, mengatakan pada hari Jumat. “Kami akan tutup sebentar.”
Matthew Street, direktur Jim terdekat untuk Fastrious, Fox 13 di Seattle bahwa staf toko perhiasan telah melarikan diri dari belakang dan pergi ke gym meminta bantuan.
Rumah rumah Seattle Macklemore bersama anak -anak di dalam; Seorang pendidik berkelahi dengan penyerang yang mencuri perhiasan

Kepala polisi tidak tahu bahwa pencurian itu terjadi sampai dia dan rincian keamanannya diperhatikan oleh mobil polisi dengan lampu dan alarm, menurut laporan Jason Rantz. (Google Maps)
Dia menambahkan bahwa ada “banyak kejutan dan kejutan” karena pencurian, yang menyebabkan kunci gym pintu sampai polisi tiba.
Para tersangka melarikan diri dari penyelundup sebelum polisi tiba di belakang. Penangkapan belum dilakukan.
Tidak ada yang terluka selama pencurian.
Klik di sini untuk mendapatkan aplikasi Fox News
Polisi Seattle mengharuskan siapa pun dengan informasi kontak dengan 206-23-5000.
Brie Stimson dari Fox News Digital berkontribusi pada laporan ini.
Berita
Embam: 5 Metode bahwa lembaga dapat mengurangi biaya kecerdasan buatan tanpa mengorbankan kinerja

Ingin lebih banyak visi yang cerdas dari kotak masuk Anda? Berlangganan buletin mingguan kami untuk mendapatkan apa yang hanya terkait dengan lembaga AI, data dan pemimpin keamanan. Berlangganan sekarang
Lembaga tampaknya menerimanya sebagai fakta penting: model kecerdasan buatan membutuhkan banyak akun; Mereka hanya menemukan cara untuk mendapatkan lebih banyak dari mereka.
Tapi seharusnya tidak seperti ini, menurut Sasha Lakkoni, Amnesty International dan iklim di Sulaman. Bagaimana jika ada cara yang lebih cerdas untuk menggunakan kecerdasan buatan? Bagaimana jika, alih -alih berusaha mencapai lebih banyak (sering tidak perlu) dan cara untuk menjalankannya, dapat fokus pada peningkatan kinerja model dan akurasi?
Pada akhirnya, pembuat model dan lembaga fokus pada masalah yang salah: mereka harus komputasi TergenangTidak lebih sulit atau lebih usaha, kata Lukoni.
“Ada cara yang lebih cerdas untuk melakukan hal -hal yang saat ini kita lakukan, karena kita sangat buta: kita membutuhkan lebih banyak fluktuasi, dan kita membutuhkan lebih banyak unit pemrosesan grafis, dan kita membutuhkan lebih banyak waktu.”
Kecerdasan buatan membatasi batasnya
Tutup daya, biaya tinggi simbol, dan penundaan dibentuk kembali. Bergabunglah dengan salon eksklusif kami untuk menemukan bagaimana perbedaan besar:
- Mengubah energi menjadi keuntungan strategis
- Mengajar penalaran yang efektif untuk keuntungan produktivitas nyata
- Membuka Pengembalian Investasi Kompetitif dengan Sistem Kecerdasan Buatan Berkelanjutan
Mengamankan tempat Anda untuk tinggal di latar depan: https://bit.ly/4mwngngo
Di bawah ini adalah lima pembelajaran utama dari pelukan yang dapat membantu institusi dari semua ukuran menggunakan kecerdasan buatan lebih efisien.
1: Ukuran yang tepat dari model misi
Hindari merusak model raksasa dan tujuan umum untuk setiap penggunaan. Model misi atau pemotongan dapat cocok, atau bahkan Lebih banyak model, secara akurat untuk beban kerja target – dengan biaya lebih rendah dan dengan konsumsi energi yang rendah.
Bahkan, Luccioni ditemukan dalam tes bahwa model tugas menggunakan energi kurang dari 20 hingga 30 kali energi tujuan umum. Dia berkata: “Karena ini adalah model yang dapat melakukan tugas ini, tidak seperti tugas apa pun yang Anda lempar, yang seringkali ini merupakan model linguistik yang besar,” katanya.
Distilasi adalah kuncinya di sini; Bentuk lengkap dapat dilatih pada awalnya dari awal dan kemudian memolesnya untuk tugas tertentu. “Deepseek R1, misalnya,” sangat besar sehingga sebagian besar organisasi tidak dapat menggunakannya “karena Anda membutuhkan setidaknya 8 unit pemrosesan resmi. Sebaliknya, versi suling dapat 10, 20, atau bahkan 30x lebih kecil dan dijalankan pada satu unit pemrosesan grafik tunggal.
Dia menunjukkan bahwa model open source membantu dalam efisiensi, karena mereka tidak membutuhkan pelatihan dari awal. Ini dibandingkan dengan hanya beberapa tahun, ketika perusahaan adalah sumber daya limbah karena mereka tidak dapat menemukan model yang mereka butuhkan; Saat ini, mereka dapat mulai dengan model dasar, menyesuaikan dan menyesuaikannya.
“Ini memberikan inovasi bersama bertahap, tidak seperti semua orang dilatih dalam model mereka pada koleksi data mereka dan terutama membuang -buang akun dalam proses ini,” kata Luxyoni.
Menjadi jelas bahwa perusahaan dengan cepat kecewa dengan Jenderal AI, karena biayanya belum sebanding dengan manfaatnya. Kasus penggunaan publik, seperti menulis email atau menyalin catatan rapat, sangat berguna. Namun, model tugas masih membutuhkan “banyak pekerjaan” karena model di luar kotak tidak memotongnya dan juga lebih mahal, seperti kata Luccioni.
Ini adalah batasan nilai tambah berikut. “Banyak perusahaan ingin melakukan tugas tertentu.” “Mereka tidak menginginkan Agi, mereka menginginkan kecerdasan tertentu. Ini adalah celah yang harus diberi makan.”
2. Buat efisiensi default
Adopsi “teori pembayaran” dalam desain sistem, anggaran pemikiran konservatif, selalu mengurangi fitur obstetri dan membutuhkan kepatuhan terhadap pola perhitungan berbakti tinggi.
Dalam ilmu kognitif, “teori pertahanan” adalah pendekatan untuk mengelola perubahan perilaku yang dirancang untuk mempengaruhi perilaku manusia dengan keterampilan. Lucioni menunjukkan bahwa “contoh gerejawi” menambahkan alat meja untuk makan di luar negeri: membuat orang memutuskan apakah mereka menginginkan peralatan plastik, alih -alih secara otomatis memasukkannya dengan setiap permintaan, dapat secara signifikan mengurangi limbah.
“Hanya untuk membuat orang memilih sesuatu untuk pembatalan sesuatu sebenarnya, itu sebenarnya mekanisme yang sangat kuat untuk mengubah perilaku orang,” kata Luxyoni.
Mekanisme virtual juga tidak perlu, karena mereka meningkatkan penggunaan, dan oleh karena itu, biaya karena model melakukan lebih dari yang mereka butuhkan. Misalnya, dengan mesin pencari umum seperti Google, ringkasan Gen AI secara otomatis diisi di bagian atas. Lucioni juga memperhatikan bahwa ketika saya baru-baru ini menggunakan GPT-5 dari Openai, model secara otomatis berfungsi dalam mode berpikir penuh pada “pertanyaan yang sangat sederhana”.
“Bagi saya, pengecualian seharusnya,” katanya. Seperti, “Apa arti hidup, lalu, saya ingin ringkasan Gen Ai. Tetapi dengan” Apa cuaca di Montreal “atau” jam kerja apa di apotek lokal? “Saya tidak memerlukan ringkasan kecerdasan buatan, namun default.
3. Meningkatkan penggunaan perangkat
Gunakan silinder. Sesuaikan ukuran pembayaran yang tepat dan pastikan mereka menghasilkan perangkat spesifik untuk mengurangi memori yang terbuang dan menarik energi.
Misalnya, perusahaan itu sendiri harus bertanya: haruskah modelnya selalu? Akankah orang mengumpulkannya dalam waktu yang sebenarnya, 100 permintaan sekaligus? Dalam hal ini, peningkatan selalu diperlukan, seperti yang ditunjukkan Lucioni. Namun, di banyak orang lain, bukan; Model ini dapat dioperasikan secara berkala untuk meningkatkan penggunaan memori, dan informasi yang salah dapat memastikan penggunaan memori yang optimal.
“Ini agak mirip dengan tantangan teknik, tetapi ini adalah tantangan yang sangat spesifik, jadi sulit untuk mengatakan,” hanya distilasi semua model, “atau” mengubah akurasi di semua model. ”
Dalam salah satu studi terbarunya, saya menemukan bahwa ukuran pembayaran tergantung pada perangkat, bahkan untuk jenis atau versi yang ditentukan. Transisi dari satu ukuran batch ke satu plus dapat meningkatkan penggunaan energi karena model membutuhkan lebih banyak bilah memori.
“Ini adalah sesuatu yang tidak terlihat orang, mereka seperti,” Oh, saya akan meningkatkan ukuran batch, “tetapi itu benar -benar datang untuk beralih semua hal yang berbeda ini, dan tiba -tiba itu sangat efektif, tetapi hanya berfungsi dalam konteks yang Anda tentukan.”
4. Memotivasi transparansi energi
Itu selalu membantu ketika orang termotivasi; Untuk tujuan ini, pelukan diluncurkan awal tahun ini Titik kekuatan kecerdasan buatan. Ini adalah cara baru untuk meningkatkan lebih banyak efisiensi energi, menggunakan sistem peringkat 1 hingga 5, dengan model paling efisien yang mendapatkan kondisi “lima bintang”.
Ini dapat dianggap “Bintang Energi untuk Kecerdasan Buatan”, dan terinspirasi oleh Program Federal yang kemungkinan akan berakhir, yang menetapkan spesifikasi efisiensi energi dan merek yang memenuhi syarat dengan logo Energy Star.
“Dua dekade yang lalu, ini adalah motivasi yang sangat positif. Orang -orang ingin mengklasifikasikan bintang -bintang, kan?” Kata Luxiouni. “Sesuatu yang mirip dengan gelar kekuatan akan menjadi hebat.”
Wajahnya yang tertanam Para pemimpin sekarang,, yang Anda rencanakan untuk memperbarui dengan model baru (Deepseek, GPT -SS) pada bulan September, dan melakukannya terus -menerus setiap 6 bulan atau lebih cepat dengan ketersediaan model baru. Lukoni mengatakan bahwa tujuannya adalah agar para pembangun model akan mempertimbangkan klasifikasi “lencana kehormatan.”
5. Refleksi tentang mentalitas “lebih banyak akun lebih baik”
Alih -alih mengejar GPU terbesar, mulailah dengan bertanya: “Apa cara paling cerdas untuk mencapai hasilnya?” Untuk banyak beban kerja, struktur yang paling cerdas dan data yang terkoordinasi mengungguli brute force.
“Saya pikir orang mungkin tidak memerlukan banyak unit pemrosesan grafis seperti yang mereka pikirkan,” kata Luxyoni. Alih -alih hanya pergi ke grup terbesar, perusahaan mendesak untuk memikirkan kembali tugas -tugas bahwa unit pemrosesan grafis akan menyelesaikan unit grafis dan mengapa mereka membutuhkannya, bagaimana mereka telah membuat jenis tugas ini sebelumnya, dan apa penambahan unit pemrosesan grafis tambahan pada akhirnya.
Dia berkata: “Ini adalah semacam perlombaan ini ke bawah di mana kita membutuhkan kelompok yang lebih besar.” “Dia berpikir tentang apa yang dia gunakan untuk kecerdasan buatan, dan teknologi apa yang Anda butuhkan, apa yang membutuhkannya?”
Tautan sumber

 Berita8 tahun ago
Berita8 tahun agoThese ’90s fashion trends are making a comeback in 2017
- Berita8 tahun ago
The final 6 ‘Game of Thrones’ episodes might feel like a full season
- Berita8 tahun ago
According to Dior Couture, this taboo fashion accessory is back
- Berita8 tahun ago
The old and New Edition cast comes together to perform
- Berita8 tahun ago
Phillies’ Aaron Altherr makes mind-boggling barehanded play
- Berita8 tahun ago
Uber and Lyft are finally available in all of New York State
- Berita8 tahun ago
Disney’s live-action Aladdin finally finds its stars
- Berita8 tahun ago
Mod turns ‘Counter-Strike’ into a ‘Tekken’ clone with fighting chickens

