
Berita
Model baru untuk Amnesty International: Bagaimana “Berpikir sebagai Peningkatan” mengarah pada model yang lebih baik untuk tujuan umum
Ingin lebih banyak visi yang cerdas dari kotak masuk Anda? Berlangganan buletin mingguan kami untuk mendapatkan apa yang hanya terkait dengan lembaga AI, data dan pemimpin keamanan. Berlangganan sekarang
Para peneliti di University of Illinois Urbana Chambine dan Virginia University telah mengembangkan struktur model baru yang dapat mengarah pada sistem kecerdasan buatan yang lebih kuat dengan kemampuan berpikir yang paling kuat.
Ditelepon Transformator berbasis energi (EBT), Arsitektur menunjukkan kemampuan normal untuk menggunakan waktu inferensi untuk menyelesaikan masalah yang kompleks. Untuk lembaga ini, ini dapat diterjemahkan ke dalam aplikasi internasional amnesti yang efektif yang dapat diedarkan pada situasi baru tanpa perlu model khusus dalam mengendalikannya.
Tantangan Berpikir Sistem 2
Dalam psikologi, pemikiran manusia sering dibagi menjadi dua posisi: sistem 1, yang cepat dan intuitif, dan sistem 2, yang lambat, dipelajari dan analitis. Model bahasa besar saat ini (LLM) unggul dalam tugas gaya pertama, tetapi industri kecerdasan buatan semakin fokus pada memungkinkan pemikiran 2 menghadapi tantangan pemikiran yang paling kompleks.
Model berpikir menggunakan banyak teknik penskalaan pada saat penalaran untuk meningkatkan kinerja mereka pada masalah sulit. Salah satu metode umum pembelajaran penguatan (RL), yang digunakan dalam model seperti Deepseek-R1 dan O-Series model dari OpenAII, adalah bonus kecerdasan buatan untuk menghasilkan simbol yang khas sampai mereka mencapai jawaban yang benar. Pendekatan lain, sering disebut N terbaik, termasuk membuat beberapa jawaban yang mungkin dan menggunakan mekanisme verifikasi untuk seleksi yang lebih baik.
Namun, metode ini memiliki cacat besar. Mereka sering terbatas pada berbagai masalah yang mudah diverifikasi, seperti matematika dan pengkodean, dan dapat menyebabkan penurunan kinerja dalam tugas -tugas lain seperti penulisan kreatif. Selain itu, Bukti Modern Ini menunjukkan bahwa metode berbasis RL mungkin tidak mengajarkan model berpikir baru, sebaliknya membuat mereka lebih cenderung menggunakan pola berpikir yang berhasil yang sudah mereka ketahui. Ini membatasi kemampuan mereka untuk memecahkan masalah yang membutuhkan eksplorasi nyata dan melampaui sistem pelatihan.
Model Berbasis Energi (EBM)
Arsitektur mengusulkan pendekatan yang berbeda berdasarkan kategori model yang dikenal sebagai EBMS. Ide dasarnya sederhana: alih -alih menghasilkan jawaban langsung, model “fungsi energi” belajar untuk bertindak sebagai hak. Fungsi ini membutuhkan input (seperti router) dan kandidat memprediksi dan menetapkan nilai, atau “energi”, untuk itu. Gelar energi rendah menunjukkan kompatibilitas tinggi, yang berarti prediksi cocok untuk input, sedangkan derajat energi tinggi menunjukkan kecocokan yang lemah.
Dengan menerapkan ini pada logika kecerdasan buatan, para peneliti menyarankan kertas Devs harus dilihat dengan “berpikir sebagai ukuran perbaikan mengenai verifikasi yang menguntungkan, yang menilai konsensus (probabilitas abnormal) antara entri dan prediksi kandidat.” Proses dimulai dengan ramalan acak, yang secara bertahap direvisi dengan mengurangi derajat energinya dan mengeksplorasi ruang solusi yang mungkin sehingga dekat dengan jawabannya sangat kompatibel. Pendekatan ini didasarkan pada prinsip bahwa memeriksa solusinya jauh lebih mudah daripada menghasilkan satu titik nol.
Desain “pusat terpusat pada” tiga tantangan utama dalam logika alamat kecerdasan buatan. Pertama, ini memungkinkan alokasi akun dinamis, yang berarti bahwa model dapat “berpikir” untuk periode yang lebih lama dalam masalah yang lebih sulit dan lebih pendek dalam masalah mudah. Kedua, EBM dapat menangani ketidakpastian secara alami untuk masalah dunia nyata karena tidak ada jawaban yang jelas. Ketiga, mereka bekerja sebagai tantangan mereka sendiri, menghilangkan kebutuhan akan model eksternal.
Tidak seperti sistem lain yang menggunakan generator dan verifikasi terpisah, EBM menggabungkan keduanya dalam satu model seragam. Fitur utama dari pengaturan ini adalah generalisasi yang lebih baik. Karena memeriksa solusi pada data baru di luar distribusi (OOD) seringkali lebih mudah daripada membuat jawaban yang benar, EBM dapat berurusan dengan lebih baik dengan skenario yang tidak dikenal.
Terlepas dari janji mereka, EBM secara historis berjuang dengan ekspansi. Untuk menyelesaikan ini, para peneliti menawarkan EBT, yang terspesialisasi Transforme Model Dirancang untuk model ini. EBTS dilatih untuk terlebih dahulu memverifikasi kompatibilitas antara konteks dan prediksi, kemudian meningkatkan prediksi sampai menemukan output energi yang lebih rendah (yang paling kompatibel). Proses ini secara efektif mensimulasikan proses berpikir untuk setiap prediksi. Para peneliti telah mengembangkan dua jenis EBT: unit unit pengkodean hanya terinspirasi oleh struktur GPT, dan model dua jalan mirip dengan Bert.

Struktur EBTS membuatnya fleksibel dan kompatibel dengan teknik waktu inferensi yang berbeda. “EBT dapat menghasilkan tempat tidur yang lebih panjang, self -loss, atau lebih baik daripada N (atau) Anda dapat mengambil sampel dari banyak EBT,” kata Alexe Gladeston, seorang mahasiswa PhD di Universitas Universitas Illinois Champin dan penulis surat kabar. “Bagian terbaiknya adalah bahwa semua kemampuan ini dipelajari selama pelatihan.”
Dompet di tempat kerja
Para peneliti membandingkan EBT dengan struktur spesifik: populer ++ adaptor Resep untuk generasi teks (metode terpisah) dan transformator proliferasi (DIT) untuk tugas -tugas seperti prediksi video dan klarifikasi gambar (metode yang sedang berlangsung). Mereka mengevaluasi model dalam kriteria utama: “mempelajari kemampuan untuk berkembang”, atau sejauh mana efisiensi mereka, dan “berpikir untuk berpikir”, yang mengukur bagaimana meningkatkan kinerja dengan lebih banyak akun pada saat penalaran.
Selama pelatihan, EBT menunjukkan efisiensi yang besar, mencapai tingkat penskalaan yang lebih tinggi hingga 35 % transformator ++ melalui data, ukuran batch, parameter, dan akun. Ini berarti bahwa EBT dapat dilatih lebih cepat dan lebih lisensi.
Setelah inferensi, EBT juga mengungguli model saat ini tentang tugas berpikir. Dengan “berpikir untuk periode yang lebih lama” (menggunakan lebih banyak langkah peningkatan) dan melakukan “identifikasi diri” (menghasilkan beberapa kandidat dan memilih satu dengan energi paling sedikit), EBTS meningkatkan 29 % lebih banyak pemodelan bahasa daripada Transformer ++. “Ini sesuai dengan tuduhan kami bahwa karena transformator tradisional nutrisi canggih tidak dapat menyesuaikan akun tambahan untuk setiap prediksi, mereka tidak dapat meningkatkan kinerja untuk setiap simbol dengan berpikir untuk periode yang lebih lama,” tulis para peneliti.
Untuk pengurangan gambar, EBTS mencapai hasil yang lebih baik daripada Dits saat menggunakan lulus 99 % lebih sedikit.
Dangka, penelitian ini menemukan bahwa EBTS adalah generalisasi yang lebih baik daripada struktur lainnya. Bahkan dengan kinerja yang sama atau lebih buruk dari sebelumnya, EBTS mengungguli model saat ini dalam tugas klinik. Keuntungan kinerja dari pemikiran System 2 adalah yang paling penting dalam data yang di luar distribusi (berbeda dari data pelatihan), yang menunjukkan bahwa EBTS sangat kuat ketika menghadapi tugas -tugas baru dan sulit.
Para peneliti menyarankan bahwa “manfaat dari pemikiran EBT tidak seragam dalam semua data, tetapi mereka berkembang secara positif dengan ukuran transformasi distribusi, dengan menyoroti pemikiran sebagai mekanisme penting untuk generalisasi yang kuat untuk melebihi distribusi pelatihan.”
Manfaat EBT penting karena dua alasan. Pertama, mereka menyarankan bahwa pada berbagai model dasar saat ini, EBTS dapat sangat mengungguli struktur transformator klasik yang digunakan dalam LLMS. Para penulis mencatat bahwa “pada skala model dasar modern yang dilatih pada data 1000x lebih banyak dengan lebih dari 1000x model yang lebih besar, kami berharap pra -kinerja EBT akan jauh lebih baik daripada resep transformator ++.”
Kedua, EBTS menunjukkan efisiensi data yang jauh lebih baik. Ini adalah fitur penting di era di mana data pelatihan berkualitas tinggi telah menjadi hambatan utama untuk memperluas ruang lingkup kecerdasan buatan. “Ketika data menjadi salah satu faktor terbatas utama dalam lebih banyak penskalaan, ini membuat EBT sangat menarik,” dan makalah menyimpulkan bahwa kertas itu.
Terlepas dari mekanisme penalaran yang berbeda, struktur EBT sebagian besar kompatibel dengan adaptor, yang memungkinkan untuk menggunakannya sebagai pengganti dalam LLM saat ini.
“EBTS sangat kompatibel dengan perangkat/kesimpulan saat ini,” kata Gladston, termasuk spekulasi decoding menggunakan model nutrisi pada kedua unit pemrosesan grafis atau TPU. Dia juga mengatakan bahwa dia dapat menjalankan akselerator khusus seperti LPU dan algoritma peningkatan seperti Flashatuth-3, atau dapat diterbitkan melalui pihak inferensi umum seperti VLLM.
Untuk pengembang dan lembaga, kemampuan berpikir yang kuat dan umum dari EBT dapat menjadikannya dasar yang kuat dan dapat diandalkan untuk membangun generasi berikutnya dari aplikasi kecerdasan buatan. “Berpikir untuk jangka waktu yang lebih lama dapat membantu hampir di hampir semua aplikasi institusi, tetapi saya pikir yang paling menarik adalah mereka yang membutuhkan keputusan, keamanan atau aplikasi yang lebih penting dengan data terbatas,” kata Gladstone.

Tautan sumber

Ingin lebih banyak visi yang cerdas dari kotak masuk Anda? Berlangganan buletin mingguan kami untuk mendapatkan apa yang hanya terkait dengan lembaga AI, data dan pemimpin keamanan. Berlangganan sekarang
Openai Itu jarang terjadi pada hari Kamis, dan tiba -tiba menghentikan keuntungan yang memungkinkan Chatgpt Pengguna untuk Buat percakapan mereka ditemukan melalui Google Dan mesin pencari lainnya. Keputusan itu datang dalam beberapa jam dari kritik media sosial yang sangat luas dan merupakan contoh yang luar biasa dari kecepatan ketakutan privasi yang dapat menghalangi pengalaman kecerdasan buatan yang baik.
Fitur, yang digambarkan Openai sebagai “Pengalaman jangka pendek“Meminta pengguna dengan memilih secara aktif dengan berbagi obrolan dan kemudian mencentang kotak untuk membuatnya mencari. Namun, refleksi cepat gagal untuk tantangan utama yang dihadapi perusahaan kecerdasan buatan: mencapai keseimbangan antara potensi manfaat dari pengetahuan umum dengan risiko nyata paparan data yang tidak diinginkan.
Kami telah menghapus keuntungan @Chatgptapp Ini memungkinkan pengguna untuk mengadakan percakapan mereka, yang dapat ditemukan oleh mesin pencari, seperti Google. Ini adalah pengalaman singkat untuk membantu orang menemukan percakapan yang bermanfaat. Fitur ini mengharuskan pengguna untuk berlangganan, pertama dengan memilih untuk mengobrol … pic.twitter.com/mgi3lf05ua
Dan (@cryps1s) 31 Juli 2025
Bagaimana ribuan percakapan chatgpt menjadi hasil pencarian Google
Kontroversi itu meletus ketika pengguna menemukan bahwa mereka dapat mencari di Google menggunakan kueri.Lokasi: chatgpt.com/share“Untuk menemukan ribuan percakapan orang asing dengan asisten kecerdasan buatan. Apa citra intim tentang bagaimana orang berinteraksi dengan kecerdasan buatan – dari permintaan duniawi untuk mendapatkan saran pembaruan kamar mandi hingga pertanyaan kesehatan pribadi yang mendalam dan dimulainya kembali yang sensitif secara profesional, banding tidak dipertukarkan.
“Pada akhirnya, kami percaya bahwa fitur ini memberikan banyak peluang bagi orang -orang untuk berbagi hal -hal yang tidak mereka inginkan secara tidak sengaja,” tim keamanan Openai menjelaskan kepada X, mengakui bahwa rappo tidak cukup untuk mencegah penyalahgunaan.
AI Impact Series kembali ke San Francisco – 5 Agustus
Tahap selanjutnya dari kecerdasan buatan di sini – apakah Anda siap? Bergabunglah dengan para pemimpin dari Block, GSK dan SAP untuk mengambil tampilan eksklusif tentang cara memulai kembali agen independen dari tugas alur kerja yayasan-dari keputusan dalam waktu yang sebenarnya untuk otomatisasi komprehensif.
Mengamankan tempat Anda sekarang – ruang terbatas: https://bit.ly/3guPlf
Kecelakaan itu mengungkapkan titik buta yang penting tentang bagaimana perusahaan kecerdasan buatan berurusan dengan desain pengalaman pengguna. Meskipun ada jaminan teknis-fitur terlibat dan membutuhkan beberapa klik untuk mengaktifkan-elemen manusia telah membuktikan masalah. Pengguna belum sepenuhnya memahami efek membuat obrolan mereka dicari atau hanya mengabaikan implikasi privasi dalam antusiasme mereka untuk bertukar pertukaran yang bermanfaat.
Sebagai seorang ahli keamanan Catatan pada x: “Gesekan untuk berbagi informasi yang mungkin harus lebih besar dari kotak seleksi atau tidak ada sama sekali.”
Undangan yang bagus untuk melepasnya dengan cepat dan diharapkan. Jika kita ingin kecerdasan buatan tersedia, kita harus menghitung bahwa sebagian besar pengguna tidak pernah membacanya.
Gesekan untuk berbagi kemungkinan informasi khusus harus lebih besar dari kotak seleksi atau tidak ada sama sekali. https://t.co/remhd1aaxy
– Wavefnx (Wavefnx) 31 Juli 2025
Kesalahan Openai mengikuti pola yang mengkhawatirkan dalam membuat kecerdasan buatan. Pada bulan September 2023, Google menghadapi kritik serupa ketika percakapan Bard AI mulai muncul dalam hasil pencarian, mendorong perusahaan untuk menerapkan langkah -langkah larangan. Meta menghadapi masalah serupa ketika beberapa pengguna meta AI tidak sengaja Menerbitkan Obrolan Pribadi ke Ringkasan PublikTerlepas dari peringatan tentang perubahan dalam kasus privasi.
Insiden ini menerangi tantangan yang lebih luas: perusahaan kecerdasan buatan dengan cepat pindah ke inovasi dan membedakan antara produk mereka, dan kadang -kadang dengan mengorbankan melindungi privasi yang kuat. Ini dapat menuntut tekanan untuk mengisi fitur baru dan mempertahankan keunggulan kompetitif yang cermat untuk skenario penyalahgunaan potensial.
Untuk pembuat keputusan di institusi, gaya ini harus menimbulkan pertanyaan berbahaya tentang perawatan yang tepat dari penjual. Jika produk AI yang dihadapi konsumen berjuang dengan elemen kontrol dasar dalam privasi, apa artinya ini untuk aplikasi bisnis yang berhubungan dengan data perusahaan sensitif?
Perusahaan apa yang perlu diketahui tentang risiko privasi chatbot ai
itu Kontroversi chatgpt Ini membawa kepentingan khusus bagi pengguna bisnis yang semakin bergantung pada asisten kecerdasan buatan untuk semuanya, mulai dari perencanaan strategis hingga analisis kompetitif. Sementara Openai menyatakan bahwa akun lembaga dan tim memiliki perlindungan privasi yang berbeda, sandungan produk konsumen menyoroti pentingnya memahami bagaimana penjual kecerdasan buatan berurusan dengan berbagi data dan menyimpannya.
Lembaga pintar harus meminta jawaban yang jelas untuk tata kelola data dari penyedia kecerdasan buatan. Pertanyaan utama meliputi: dalam kondisi bahwa pembicaraan mungkin tersedia untuk pihak ketiga? Apa saja kontrol untuk mencegah paparan yang tidak disengaja? Seberapa cepat perusahaan menanggapi kecelakaan privasi?
Insiden itu juga menunjukkan sifat viral dari pelanggaran privasi di era media sosial. Dalam beberapa jam setelah penemuan awal, cerita menyebar X.com (sebelumnya Twitter)Dan Saya menjawabPublikasi teknologi utama, menguatkan reputasi dan memaksa tangan Openai.
Dilema Inovasi: Membangun Keuntungan AI Berguna tanpa mengurangi privasi pengguna
Visi Openai tentang fitur pencarian tidak rusak. Kemampuan untuk menemukan percakapan kecerdasan buatan yang sangat berguna dapat membantu menemukan solusi untuk masalah umum, mirip dengan bagaimana Kelebihan Ini telah menjadi sumber yang sangat berharga bagi pemrogram. Konsep membangun basis penelitian yang tunduk pada kecerdasan buatan memiliki keuntungan.
Namun, eksekusi mengungkapkan ketegangan penting dalam mengembangkan kecerdasan buatan. Perusahaan ingin memanfaatkan kecerdasan kolektif yang dihasilkan dari reaksi pengguna dengan perlindungan privasi individu. Menemukan keseimbangan yang benar membutuhkan pendekatan yang lebih canggih daripada kotak seleksi sederhana.
Satu pengguna di x Itu merebut kompleksitas: “Jangan mengurangi pekerjaan karena orang tidak dapat membaca. Standarnya bagus dan aman, Anda harus berdiri di tanah Anda.” Tetapi yang lain tidak setuju, seperti yang ditunjukkan oleh salah satu dari mereka bahwa “isi chatgpt seringkali lebih sensitif daripada rekening bank.”
Pakar pengembangan produk, Jeffrey Emmanuel, juga menyarankan bahwa X: “Post -death harus pasti dan mengubah pendekatan untuk melanjutkan pertanyaan” tentang hal buruk jika 20 % dari populasi lebih buruk dan disalahgunakan fitur ini? “Itu merencanakannya.”
Tentu saja, Anda harus melakukan post -mati dalam hal ini dan mengubah pendekatan untuk bergerak maju dalam pertanyaan, “Seberapa buruk jika lebih dari 20 % dari populasi salah paham fitur ini dan menyalahgunakannya?” Itu merencanakannya.
Jeffrey Emmanuel (Doodlestein) 31 Juli 2025
Privasi dasar yang harus diterapkan oleh setiap perusahaan internasional amnesti
itu Bencana pencarian chatgpt Ini memberikan banyak pelajaran penting untuk perusahaan intelijen buatan dan pelanggan di lembaga. Pertama, pengaturan privasi virtual sangat penting. Fitur yang dapat mengungkapkan informasi sensitif harus memerlukan persetujuan yang jelas dan terinformasi dengan peringatan yang jelas tentang konsekuensi yang mungkin.
Kedua, desain antarmuka pengguna memainkan peran yang menentukan dalam perlindungan privasi. Multile -Steps dapat, bahkan ketika mereka secara teknis aman, dapat menyebabkan kesalahan pengguna dengan konsekuensi yang parah. Perusahaan intelijen buatan perlu berinvestasi besar -besaran dalam membuat kontrol privasi pribadi dan intuitif.
Ketiga, kemampuan respons cepat diperlukan. Kemampuan Openai untuk mencerminkan kursus pelatihan dalam beberapa jam dari kerusakan paling serius pada reputasi, tetapi kecelakaan itu masih menimbulkan pertanyaan tentang proses meninjau fitur mereka.
Bagaimana institusi dapat melindungi diri dari kegagalan privasi kecerdasan buatan
Karena kecerdasan buatan semakin terintegrasi ke dalam proses komersial, kecelakaan privasi seperti ini menjadi lebih tergantung. Risiko meningkat secara dramatis ketika percakapan terbuka mencakup strategi untuk perusahaan, data pelanggan atau informasi alih -alih pertanyaan pribadi tentang perbaikan rumah.
Lembaga berpikiran depan harus menganggap kejadian ini sebagai undangan untuk bangun untuk memperkuat kerangka tata kelola buatan. Ini termasuk penilaian komprehensif tentang pengaruh privasi sebelum menerbitkan alat AI baru, menetapkan kebijakan yang jelas tentang informasi yang dapat dibagikan dengan sistem kecerdasan buatan, dan memelihara stok terperinci dari aplikasi kecerdasan buatan di seluruh organisasi.
Anda harus belajar membuat kecerdasan buatan yang lebih luas daripada openai. Karena alat -alat ini menjadi lebih kuat dan perangkat di mana -mana, margin kesalahan dalam melindungi privasi masih menyusut. Ada kemungkinan bahwa perusahaan yang memberikan prioritas pada desain privasi yang dipelajari sejak awal akan menikmati keunggulan kompetitif yang besar pada mereka yang berurusan dengan privasi sebagai ide selanjutnya.
Biaya tinggi kepercayaan diri dalam kecerdasan buatan
itu Episode chatgpt sedang mencari Ini menjelaskan fakta dasar tentang mengadopsi kecerdasan buatan: sulit untuk membangun kembali kepercayaan diri, setelah rusak, luar biasa. Meskipun respons cepat Openai mungkin mengandung kerusakan langsung, kecelakaan itu merupakan pengingat bahwa kegagalan privasi dapat dengan cepat membanjiri pencapaian teknis.
Untuk produsen berdasarkan janji untuk mengubah cara kita bekerja dan hidup, menjaga kepercayaan diri pengguna bukan hanya hal yang menyenangkan-itu adalah persyaratan eksistensial. Dengan perluasan yang berkelanjutan dari kemampuan kecerdasan buatan, perusahaan yang berhasil adalah mereka yang membuktikan bahwa mereka dapat dipecat dengan tanggung jawab, dan menempatkan privasi pengguna dan keselamatan di pusat pengembangan produk mereka.
Pertanyaannya sekarang adalah apakah industri kecerdasan buatan akan belajar dari panggilan privasi terakhir atau terus tersandung melalui skandal yang sama. Karena dalam perlombaan untuk membangun kecerdasan buatan yang paling berguna, Anda mungkin menemukan perusahaan yang lupa untuk melindungi pengguna mereka sendiri bekerja sendiri.
Tautan sumber
Berita
Seorang pria yang mengendarai kendaraan curian di koridor seluler di bandara Boufalo di video viral

baruAnda sekarang dapat mendengarkan Fox News!
Sebuah adegan aneh muncul di Bandara Internasional Buffalo Niagra di New York pada Senin pagi ketika seorang pria mengemudi dalam keadaan mabuk kereta golf curian ke koridor yang bergerak.
Passeries mengambil momen dalam video emas sejak itu.
Video dimulai dengan seorang pria, yang kemudian diidentifikasi sebagai Kevin Singing, 29, dari Wyoming, mengendarai kereta golf dari koridor seluler di bandara, menurut stasiun setempat melaporkan WKBW.
Dosa kemudian berubah menjadi gerobak dan mengembalikannya ke koridor yang bergerak, dan kehilangan banyak “tanda tanah basah” dalam proses ini.
The Nark’s Baggage Belt memegang anak laki -laki dua tahun, dan petugas pindah ke tempat kerja
Seorang pria di Wyoming ditangkap setelah mengendarai kendaraan golf curian di Bandara Internasional Buffalo Niagra, sementara ia diklaim pada 28 Juli 2025. (Thomas Brennan/TMX)
Saat mendekati koridor, dosa berbaris gerobak dan diarahkan dengan roda pengemudi di tepi logam, dan roda oleh penumpang di sabuk transportasi.
Ketika Sinning memimpin orang yang mengambil video, ia muncul dalam keadaan takjub, dan menantikan langsung dengan sedikit gairah.

Seorang pria di Wyoming ditangkap setelah mengendarai kendaraan golf curian di Bandara Internasional Buffalo Niagra, sementara ia diklaim pada 28 Juli 2025. (Thomas Brennan/TMX)
Oh, Kanada: Seorang pria Toronto meminta rasa bersalah setelah bandara tanah menyerang agen TSA di Miami ditangkap di video itu
WKBW juga menyatakan bahwa para petugas menangkap dosa di ujung jalan yang bergerak.
Menurut stasiun itu, polisi mengatakan bahwa dosa jelas disiram.

Jalan setapak rusak selama dugaan perjalanan mabuk. (Thomas Brennan/TMX)
Mantan Kepala Polisi California menuduh suasana selokan setelah dia menjatuhkan sebotol penuh celah
Koridor tampaknya rusak selama perjalanan liar.
Dia dituduh berdosa atas cedera kriminal, perilaku yang tidak terkendali, kepemilikan pidana atas barang curian, ketidaknyamanan pidana dan pencurian besar, menurut WKBW.
Klik di sini untuk mendapatkan aplikasi Fox News
Fox News Digital telah berkomunikasi dengan Niagara Frontier Transport Authority (NFTA) untuk mengomentari masalah ini.
Ingin lebih banyak visi yang cerdas dari kotak masuk Anda? Berlangganan buletin mingguan kami untuk mendapatkan apa yang hanya terkait dengan lembaga AI, data dan pemimpin keamanan. Berlangganan sekarang
Deep Cogito, AI Research Startup, adalah markas besar San Francisco, yang didirikan oleh mantan swogon, Hari ini saya merilis empat model linguistik terbuka baru (LLMS) Ini mencoba sesuatu untuk dilakukan dengan beberapa: pelajari cara berpikir lebih efektif dari waktu ke waktu – dan memperbaikinya sendiri.
Model, Itu dirilis sebagai bagian dari keluarga V2 Cogito, Ini berkisar antara 70 miliar hingga 671 miliar guru dan tersedia untuk pengembang dan lembaga kecerdasan buatan untuk digunakan mengingat kombinasi lisensi terbatas dan sepenuhnya terbuka. Termasuk:
- Cogite V2-70B (padat)
- Cogito V2-109B (ahli campuran)
- Cogito V2-405B (padat)
- Cogito V2-671B (Pakar Pakar)
Seri Cogito V2 mencakup keduanya berat Dan Campuran ahli (mee) Model, setiap kesempatan untuk memenuhi kebutuhan yang berbeda. Model padat, seperti variabel 70B dan 405B, aktif, semua parameter pada setiap lintasan, yang membuatnya lebih mudah diprediksi dan lebih mudah dipublikasikan melalui berbagai perangkat.
Itu sempurna untuk Aplikasi rendah, penyesuaian, dan lingkungan dengan unit pemrosesan grafis terbatas. Model MEE, seperti versi 109b dan 671b, gunakan mekanisme panduan yang tersebar untuk mengaktifkan beberapa sub -networks “para ahli” yang berspesialisasi pada satu waktu, memungkinkan banyak hal Ukuran total model terbesar Tanpa kenaikan relatif dalam biaya akun.
AI Impact Series kembali ke San Francisco – 5 Agustus
Tahap selanjutnya dari kecerdasan buatan di sini – apakah Anda siap? Bergabunglah dengan para pemimpin dari Block, GSK dan SAP untuk mengambil tampilan eksklusif tentang cara memulai kembali agen independen dari tugas alur kerja yayasan-dari keputusan dalam waktu yang sebenarnya untuk otomatisasi komprehensif.
Mengamankan tempat Anda sekarang – ruang terbatas: https://bit.ly/3guPlf
Ini membuatnya cocok Tugas Inferensi Kinerja TinggiPenelitian dalam pemikiran kompleks, atau presentasi Keakuratan tingkat perbatasan dengan mengorbankan waktu operasi yang lebih rendah. Di Cogito V2, model MEE 671B berfungsi sebagai yang terbaik, dan manfaat dari efisiensi dan efisiensinya dalam mengarahkan untuk mencocokkan atau memotong model terbuka terkemuka pada standar – dengan penggunaan rantai berpikir jauh lebih pendek.
Sekarang tersedia Sulaman Untuk diunduh dan digunakan oleh perusahaan dan seterusnya Ketidakpastian untuk Penggunaan Lokal OnlineAtau bagi mereka yang tidak dapat meng -host kesimpulan model pada perangkat mereka sendiri, melalui antarmuka API (API) dari Bersama -sama, Amnesty InternationalDan Basis Dan Runbod.
Ada juga kuantitas8 bit Floating Point (FP8)“Versi 671B, yang mengurangi volume angka yang digunakan untuk mewakili parameter model dari 16 bit menjadi 8 bit, membantu pengguna menjalankan model besar lebih cepat, lebih murah dan lebih mudah perangkat-kadang-kadang dengan kinerja yang hampir tidak terputus, 95-99 %. Itu bisa sedikit terdegradasi dari akurasi modelTerutama untuk tugas yang membutuhkan akurasi yang akurat (misalnya, beberapa masalah matematika atau pemikiran).
Setiap empat cModel Ogito V2 dirancang sebagai sistem berpikir hibrida: mereka dapat segera merespons untuk menanyakan, atau ketika dibutuhkan, mencerminkan secara internal sebelum menjawab.
Sangat penting bahwa refleksi ini bukan hanya waktu operasi – tetapi juga dalam proses pelatihan itu sendiri.
Model -model ini dilatih untuk menyerap pemikiran mereka. Ini berarti bahwa jalan yang sama yang mereka ambil untuk mencapai jawaban – langkah mental, jika diizinkan untuk berbicara – disuling lagi dalam bobot model.
Seiring waktu, Mereka sudah mempelajari setiap garis pemikiran penting dan yang tidak.
Blog Cogito yang dalam, “para peneliti”, juga memperhatikan bentuk “Moster yang berkelok -kelok” untuk dapat mencapai jawabannya, dan sebaliknya, mengembangkan intuisi yang lebih kuat untuk jalur penelitian yang benar untuk proses berpikir. “
Dan hasilnya, seperti yang Anda klaim dalam kogito, adalah Pemikiran lebih cepat, lebih efisien dan peningkatan kinerja, Bahkan dalam situasi “standar” yang disebut SO.
Stimulasi intelijen diri
Sementara banyak orang di komunitas kecerdasan buatan menghadapi perusahaan sekarang, Deep Cogito diam -diam dibangun selama lebih dari setahun.
Perusahaan ini keluar dari Stealth pada bulan April 2025 dengan serangkaian model open source yang dilatih pada meta LAMA 3.2. Versi awal ini menunjukkan hasil yang menjanjikan.
menyukai VentureBeat Sebelumnya dilaporkan bahwa Cogito V1 (3B dan 8B) terkecil melampaui rekan Lama 3 melalui beberapa kriteria – kadang -kadang dengan margin lebar.
CEO dan co -founder COGITO DEED DRISHAN ARERA Insinyur LLM yang sebelumnya dijelaskan di Google-Tujuan Jangka Panjang Perusahaan adalah untuk membangun Model yang dapat menyebabkan dan meningkat dengan setiap pengulanganSangat mirip dengan bagaimana Alfago meningkatkan strateginya melalui permainan diri.
Ini menggantikan metode dasar cogito dalam, distilasi dan amplifikasi (IDA), klaim tulisan tangan atau stabil dengan visi model canggih.
Apa itu “intuisi”?
Dengan Cogito V2, tim mengambil episode ini jauh lebih luas. Gagasan sentralnya sederhana: Berpikir tidak hanya merupakan alat untuk waktu inferensi, tetapi lebih harus menjadi bagian dari kecerdasan dasar model.
Jadi perusahaan telah menerapkan sistem di mana model menjalankan rantai berpikir selama pelatihan – kemudian dilatih dalam ide -ide perantara.
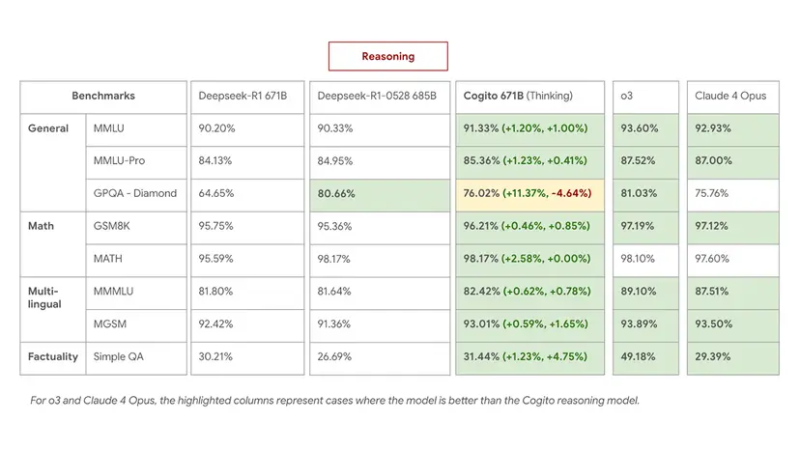
Proses ini memberikan perbaikan konkret, sesuai dengan standar internal. Model MILPSTION 671B (MIE) mengungguli kinerja mendalam R1 dalam tugas berpikir, mencocokkan atau mengatasi 0528 terbaru dengan penggunaan rantai berpikir yang lebih pendek sebesar 60 %.
Pada MMLU, GSM8K dan MGSM, Cogito 671B MEE sama dengan gaya terbuka terbaik seperti QWEN1.5-72B dan Deepseek V3, dan pergi ke tingkat kinerja model tertutup seperti Claude 4 Opus dan O3.
khususnya:
- Cogito 671b MEE (Mode Berpikir) Deepseek R1 0528 Pencocokan melalui QA multi -bahasa dan tugas pengetahuan umum, dan mengungguli dalam strategi dan diskon logis.
- Dalam posisi non -musimDepsek v3 0324, menunjukkan bahwa intuisi suling membawa bobot yang nyata bahkan tanpa jalur berpikir yang diperpanjang.
- Kemampuan model untuk menyelesaikan pemikiran lebih sedikit langkah juga merupakan efek dari kursus sungai: biaya inferensi rendah dan waktu respons yang lebih cepat pada klaim kompleks.
Arora menjelaskan ini sebagai perbedaan antara mencari jalan dengan imbalan mengetahui di mana letak tujuan.
“Karena model Cogito mengembangkan intuisi yang lebih baik untuk jalan yang harus diambil saat mencari pada saat penalaran, mereka memiliki 60 % rantai berpikir yang lebih pendek daripada Deepseek R1”. Tentang topik di x Mengumumkan model V2 baru.
Apa saja jenis tugas yang diungguli oleh model Cogito yang dalam saat menggunakan intuisi perangkat mereka?
Beberapa contoh paling persuasif dari tes internal Cogito V2 persis seperti yang muncul dalam digunakan.
Dalam klaim matematika yang berat, pengguna bertanya apakah kereta yang bergerak pada 80 mil per jam dapat mencapai kota 240 mil dalam waktu kurang dari 2,5 jam.
Sementara banyak model meniru akun langkah demi langkah dan kadang -kadang membuat kesalahan konversi unit, Cogito 671b mencerminkan secara internal, menentukan bahwa 240 ÷ 80 = 3 jam, dan disimpulkan dengan benar bahwa kereta itu adalah Tidak mungkin Itu tiba tepat waktu. Ia melakukannya dengan pemikiran interior pendek – di bawah 100 ikon – dibandingkan dengan 200+ yang digunakan oleh Deepsek R1 untuk mencapai jawaban yang sama.
Dalam contoh lain yang mencakup pemikiran hukum, pengguna bertanya apakah putusan Mahkamah Agung AS akan berlaku untuk masalah virtual yang mencakup penelitian dan penyitaan. Posisi berpikir di Cogito menyoroti logika dua langkah: menentukan apakah lantai default cocok dengan sebelumnya, kemudian jelaskan alasannya atau tidak. Model ini mencapai jawaban yang akurat dengan justifikasi yang jelas – jenis pemikiran interpretatif yang masih banyak diperangi LLM.
Tugas lain menunjukkan peningkatan dalam menangani misteri. Dalam pertanyaan multi-hukum klasik- “Jika dia bukan ibu dari Bob, dan Bob adalah ayah Charlie, apa yang bukan untuk Charlie?” Model sering terjalin dalam kata ganti. Model Cogito V2 dengan benar memperkenalkan Alice sebagai nenek Charlie, bahkan dalam perubahan yang sedikit diformulasikan ketika model terbuka lainnya tersandung.
Efisiensi luas
Meskipun ukurannya sangat besar dari model baru, Deep Cogito mengklaim bahwa itu melatih semua delapan model Cogito – termasuk pos pemeriksaan V1 yang lebih kecil 100 juta dolar selain beberapa model terkemuka Openai.
Ini termasuk pembuatan data, peningkatan sintetis, infrastruktur, dan lebih dari 1.000 percobaan pelatihan. Dibandingkan dengan anggaran sembilan angka untuk model perbatasan lainnya, mereka adalah bagian dari pengeluaran khas.
Arora mengaitkan aset ini dengan tesis dasar perusahaan: model yang paling cerdas membutuhkan perangkat kontrol yang lebih baik, bukan lebih banyak simbol.
Dengan mengajarkan model untuk mengatasi jalur pemikiran yang berlebih atau menyesatkan, Cogito V2 memberikan kinerja yang lebih kuat tanpa waktu daur ulang.
Ini adalah barter yang bermakna bagi pengguna yang mengoperasikan model pada perangkat infrastruktur atau API di mana jintan dan biaya berada.
Apa berikut untuk Deep Cogito dan V2?
Versi Cogito V2 bukan produk final tetapi berulang. Arora menggambarkan peta jalan perusahaan sebagai “mendaki bukit” – model yang Anda buat, belajar dari efek berpikir, distilasi, dan ulangi episode. Seiring waktu, setiap gaya menjadi batu untuk bergerak bagi yang lain.
Setiap model DEP Cogito adalah open source, dan perusahaan mengatakan ini akan tetap benar untuk pengulangan di masa depan.
Memang, karyanya menarik perhatian dan dukungan dari para pendukung seperti Eric Vishria dari Benchmark dan South Park Commons Agarwal.
Wajah memeluk, bersama AI, Runpod, Baseten, tim Llama Meta dan Lepas Luang.
Untuk pengembang, peneliti dan tim lembaga, Model sekarang tersedia. Pengembang Ini dapat dioperasikan secara lokal, membandingkan kondisi, atau menyingkirkan kasus penggunaan tertentu.
Untuk masyarakat open-source yang lebih luas, Cogito V2 menawarkan lebih dari sekadar pemenang baru dengan cara yang berbeda untuk membangun intelijen. Bukan dengan berpikir keras, tetapi dengan mempelajari cara berpikir lebih baik.
Tautan sumber

 Berita8 tahun ago
Berita8 tahun agoThese ’90s fashion trends are making a comeback in 2017
- Berita8 tahun ago
The final 6 ‘Game of Thrones’ episodes might feel like a full season
- Berita8 tahun ago
According to Dior Couture, this taboo fashion accessory is back
- Berita8 tahun ago
The old and New Edition cast comes together to perform
- Berita8 tahun ago
Phillies’ Aaron Altherr makes mind-boggling barehanded play
- Berita8 tahun ago
Uber and Lyft are finally available in all of New York State
- Berita8 tahun ago
Disney’s live-action Aladdin finally finds its stars
- Berita8 tahun ago
Mod turns ‘Counter-Strike’ into a ‘Tekken’ clone with fighting chickens

