
Berita
Model Cogito V2 memiliki intuisi diri
Ingin lebih banyak visi yang cerdas dari kotak masuk Anda? Berlangganan buletin mingguan kami untuk mendapatkan apa yang hanya terkait dengan lembaga AI, data dan pemimpin keamanan. Berlangganan sekarang
Deep Cogito, AI Research Startup, adalah markas besar San Francisco, yang didirikan oleh mantan swogon, Hari ini saya merilis empat model linguistik terbuka baru (LLMS) Ini mencoba sesuatu untuk dilakukan dengan beberapa: pelajari cara berpikir lebih efektif dari waktu ke waktu – dan memperbaikinya sendiri.
Model, Itu dirilis sebagai bagian dari keluarga V2 Cogito, Ini berkisar antara 70 miliar hingga 671 miliar guru dan tersedia untuk pengembang dan lembaga kecerdasan buatan untuk digunakan mengingat kombinasi lisensi terbatas dan sepenuhnya terbuka. Termasuk:
- Cogite V2-70B (padat)
- Cogito V2-109B (ahli campuran)
- Cogito V2-405B (padat)
- Cogito V2-671B (Pakar Pakar)
Seri Cogito V2 mencakup keduanya berat Dan Campuran ahli (mee) Model, setiap kesempatan untuk memenuhi kebutuhan yang berbeda. Model padat, seperti variabel 70B dan 405B, aktif, semua parameter pada setiap lintasan, yang membuatnya lebih mudah diprediksi dan lebih mudah dipublikasikan melalui berbagai perangkat.
Itu sempurna untuk Aplikasi rendah, penyesuaian, dan lingkungan dengan unit pemrosesan grafis terbatas. Model MEE, seperti versi 109b dan 671b, gunakan mekanisme panduan yang tersebar untuk mengaktifkan beberapa sub -networks “para ahli” yang berspesialisasi pada satu waktu, memungkinkan banyak hal Ukuran total model terbesar Tanpa kenaikan relatif dalam biaya akun.
AI Impact Series kembali ke San Francisco – 5 Agustus
Tahap selanjutnya dari kecerdasan buatan di sini – apakah Anda siap? Bergabunglah dengan para pemimpin dari Block, GSK dan SAP untuk mengambil tampilan eksklusif tentang cara memulai kembali agen independen dari tugas alur kerja yayasan-dari keputusan dalam waktu yang sebenarnya untuk otomatisasi komprehensif.
Mengamankan tempat Anda sekarang – ruang terbatas: https://bit.ly/3guPlf
Ini membuatnya cocok Tugas Inferensi Kinerja TinggiPenelitian dalam pemikiran kompleks, atau presentasi Keakuratan tingkat perbatasan dengan mengorbankan waktu operasi yang lebih rendah. Di Cogito V2, model MEE 671B berfungsi sebagai yang terbaik, dan manfaat dari efisiensi dan efisiensinya dalam mengarahkan untuk mencocokkan atau memotong model terbuka terkemuka pada standar – dengan penggunaan rantai berpikir jauh lebih pendek.
Sekarang tersedia Sulaman Untuk diunduh dan digunakan oleh perusahaan dan seterusnya Ketidakpastian untuk Penggunaan Lokal OnlineAtau bagi mereka yang tidak dapat meng -host kesimpulan model pada perangkat mereka sendiri, melalui antarmuka API (API) dari Bersama -sama, Amnesty InternationalDan Basis Dan Runbod.
Ada juga kuantitas8 bit Floating Point (FP8)“Versi 671B, yang mengurangi volume angka yang digunakan untuk mewakili parameter model dari 16 bit menjadi 8 bit, membantu pengguna menjalankan model besar lebih cepat, lebih murah dan lebih mudah perangkat-kadang-kadang dengan kinerja yang hampir tidak terputus, 95-99 %. Itu bisa sedikit terdegradasi dari akurasi modelTerutama untuk tugas yang membutuhkan akurasi yang akurat (misalnya, beberapa masalah matematika atau pemikiran).
Setiap empat cModel Ogito V2 dirancang sebagai sistem berpikir hibrida: mereka dapat segera merespons untuk menanyakan, atau ketika dibutuhkan, mencerminkan secara internal sebelum menjawab.
Sangat penting bahwa refleksi ini bukan hanya waktu operasi – tetapi juga dalam proses pelatihan itu sendiri.
Model -model ini dilatih untuk menyerap pemikiran mereka. Ini berarti bahwa jalan yang sama yang mereka ambil untuk mencapai jawaban – langkah mental, jika diizinkan untuk berbicara – disuling lagi dalam bobot model.
Seiring waktu, Mereka sudah mempelajari setiap garis pemikiran penting dan yang tidak.
Blog Cogito yang dalam, “para peneliti”, juga memperhatikan bentuk “Moster yang berkelok -kelok” untuk dapat mencapai jawabannya, dan sebaliknya, mengembangkan intuisi yang lebih kuat untuk jalur penelitian yang benar untuk proses berpikir. “
Dan hasilnya, seperti yang Anda klaim dalam kogito, adalah Pemikiran lebih cepat, lebih efisien dan peningkatan kinerja, Bahkan dalam situasi “standar” yang disebut SO.
Stimulasi intelijen diri
Sementara banyak orang di komunitas kecerdasan buatan menghadapi perusahaan sekarang, Deep Cogito diam -diam dibangun selama lebih dari setahun.
Perusahaan ini keluar dari Stealth pada bulan April 2025 dengan serangkaian model open source yang dilatih pada meta LAMA 3.2. Versi awal ini menunjukkan hasil yang menjanjikan.
menyukai VentureBeat Sebelumnya dilaporkan bahwa Cogito V1 (3B dan 8B) terkecil melampaui rekan Lama 3 melalui beberapa kriteria – kadang -kadang dengan margin lebar.
CEO dan co -founder COGITO DEED DRISHAN ARERA Insinyur LLM yang sebelumnya dijelaskan di Google-Tujuan Jangka Panjang Perusahaan adalah untuk membangun Model yang dapat menyebabkan dan meningkat dengan setiap pengulanganSangat mirip dengan bagaimana Alfago meningkatkan strateginya melalui permainan diri.
Ini menggantikan metode dasar cogito dalam, distilasi dan amplifikasi (IDA), klaim tulisan tangan atau stabil dengan visi model canggih.
Apa itu “intuisi”?
Dengan Cogito V2, tim mengambil episode ini jauh lebih luas. Gagasan sentralnya sederhana: Berpikir tidak hanya merupakan alat untuk waktu inferensi, tetapi lebih harus menjadi bagian dari kecerdasan dasar model.
Jadi perusahaan telah menerapkan sistem di mana model menjalankan rantai berpikir selama pelatihan – kemudian dilatih dalam ide -ide perantara.
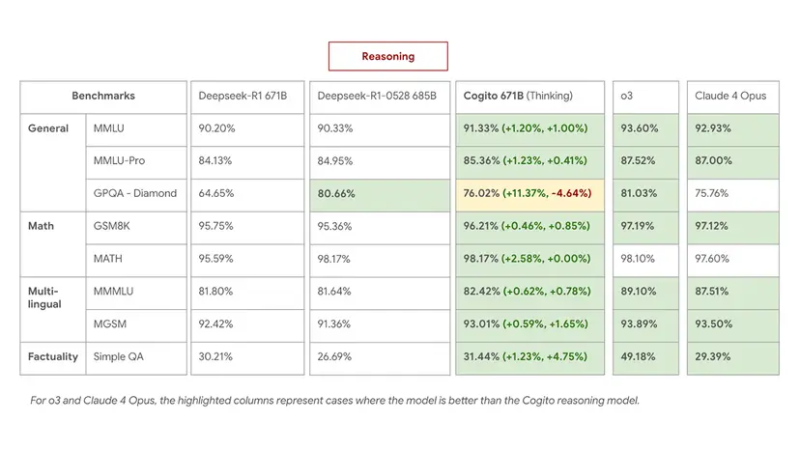
Proses ini memberikan perbaikan konkret, sesuai dengan standar internal. Model MILPSTION 671B (MIE) mengungguli kinerja mendalam R1 dalam tugas berpikir, mencocokkan atau mengatasi 0528 terbaru dengan penggunaan rantai berpikir yang lebih pendek sebesar 60 %.
Pada MMLU, GSM8K dan MGSM, Cogito 671B MEE sama dengan gaya terbuka terbaik seperti QWEN1.5-72B dan Deepseek V3, dan pergi ke tingkat kinerja model tertutup seperti Claude 4 Opus dan O3.
khususnya:
- Cogito 671b MEE (Mode Berpikir) Deepseek R1 0528 Pencocokan melalui QA multi -bahasa dan tugas pengetahuan umum, dan mengungguli dalam strategi dan diskon logis.
- Dalam posisi non -musimDepsek v3 0324, menunjukkan bahwa intuisi suling membawa bobot yang nyata bahkan tanpa jalur berpikir yang diperpanjang.
- Kemampuan model untuk menyelesaikan pemikiran lebih sedikit langkah juga merupakan efek dari kursus sungai: biaya inferensi rendah dan waktu respons yang lebih cepat pada klaim kompleks.
Arora menjelaskan ini sebagai perbedaan antara mencari jalan dengan imbalan mengetahui di mana letak tujuan.
“Karena model Cogito mengembangkan intuisi yang lebih baik untuk jalan yang harus diambil saat mencari pada saat penalaran, mereka memiliki 60 % rantai berpikir yang lebih pendek daripada Deepseek R1”. Tentang topik di x Mengumumkan model V2 baru.
Apa saja jenis tugas yang diungguli oleh model Cogito yang dalam saat menggunakan intuisi perangkat mereka?
Beberapa contoh paling persuasif dari tes internal Cogito V2 persis seperti yang muncul dalam digunakan.
Dalam klaim matematika yang berat, pengguna bertanya apakah kereta yang bergerak pada 80 mil per jam dapat mencapai kota 240 mil dalam waktu kurang dari 2,5 jam.
Sementara banyak model meniru akun langkah demi langkah dan kadang -kadang membuat kesalahan konversi unit, Cogito 671b mencerminkan secara internal, menentukan bahwa 240 ÷ 80 = 3 jam, dan disimpulkan dengan benar bahwa kereta itu adalah Tidak mungkin Itu tiba tepat waktu. Ia melakukannya dengan pemikiran interior pendek – di bawah 100 ikon – dibandingkan dengan 200+ yang digunakan oleh Deepsek R1 untuk mencapai jawaban yang sama.
Dalam contoh lain yang mencakup pemikiran hukum, pengguna bertanya apakah putusan Mahkamah Agung AS akan berlaku untuk masalah virtual yang mencakup penelitian dan penyitaan. Posisi berpikir di Cogito menyoroti logika dua langkah: menentukan apakah lantai default cocok dengan sebelumnya, kemudian jelaskan alasannya atau tidak. Model ini mencapai jawaban yang akurat dengan justifikasi yang jelas – jenis pemikiran interpretatif yang masih banyak diperangi LLM.
Tugas lain menunjukkan peningkatan dalam menangani misteri. Dalam pertanyaan multi-hukum klasik- “Jika dia bukan ibu dari Bob, dan Bob adalah ayah Charlie, apa yang bukan untuk Charlie?” Model sering terjalin dalam kata ganti. Model Cogito V2 dengan benar memperkenalkan Alice sebagai nenek Charlie, bahkan dalam perubahan yang sedikit diformulasikan ketika model terbuka lainnya tersandung.
Efisiensi luas
Meskipun ukurannya sangat besar dari model baru, Deep Cogito mengklaim bahwa itu melatih semua delapan model Cogito – termasuk pos pemeriksaan V1 yang lebih kecil 100 juta dolar selain beberapa model terkemuka Openai.
Ini termasuk pembuatan data, peningkatan sintetis, infrastruktur, dan lebih dari 1.000 percobaan pelatihan. Dibandingkan dengan anggaran sembilan angka untuk model perbatasan lainnya, mereka adalah bagian dari pengeluaran khas.
Arora mengaitkan aset ini dengan tesis dasar perusahaan: model yang paling cerdas membutuhkan perangkat kontrol yang lebih baik, bukan lebih banyak simbol.
Dengan mengajarkan model untuk mengatasi jalur pemikiran yang berlebih atau menyesatkan, Cogito V2 memberikan kinerja yang lebih kuat tanpa waktu daur ulang.
Ini adalah barter yang bermakna bagi pengguna yang mengoperasikan model pada perangkat infrastruktur atau API di mana jintan dan biaya berada.
Apa berikut untuk Deep Cogito dan V2?
Versi Cogito V2 bukan produk final tetapi berulang. Arora menggambarkan peta jalan perusahaan sebagai “mendaki bukit” – model yang Anda buat, belajar dari efek berpikir, distilasi, dan ulangi episode. Seiring waktu, setiap gaya menjadi batu untuk bergerak bagi yang lain.
Setiap model DEP Cogito adalah open source, dan perusahaan mengatakan ini akan tetap benar untuk pengulangan di masa depan.
Memang, karyanya menarik perhatian dan dukungan dari para pendukung seperti Eric Vishria dari Benchmark dan South Park Commons Agarwal.
Wajah memeluk, bersama AI, Runpod, Baseten, tim Llama Meta dan Lepas Luang.
Untuk pengembang, peneliti dan tim lembaga, Model sekarang tersedia. Pengembang Ini dapat dioperasikan secara lokal, membandingkan kondisi, atau menyingkirkan kasus penggunaan tertentu.
Untuk masyarakat open-source yang lebih luas, Cogito V2 menawarkan lebih dari sekadar pemenang baru dengan cara yang berbeda untuk membangun intelijen. Bukan dengan berpikir keras, tetapi dengan mempelajari cara berpikir lebih baik.

Tautan sumber
Berita
Saya mendengar tentang alat “riset mendalam” kecerdasan buatan … sekarang manus meluncurkan “penelitian luas” yang berputar lebih dari 100 agen untuk mencapai web untuk Anda

Ingin lebih banyak visi yang cerdas dari kotak masuk Anda? Berlangganan buletin mingguan kami untuk mendapatkan apa yang hanya terkait dengan lembaga AI, data dan pemimpin keamanan. Berlangganan sekarang
Startup AI Singapura ManusBerita utama surat kabar awal tahun ini karena pendekatannya terhadap platform kebetulan multi -agen untuk konsumen dan “profesional” (profesional yang ingin mengoperasikan operasi kerja), kembali ke penggunaan baru yang menarik dari teknologinya.
Sementara banyak penyedia kecerdasan buatan utama seperti OpenAi dan Google dan xi “Penelitian mendalam” atau “peneliti yang dalam” telah meluncurkan faktor -faktor kecerdasan buatan yang menghasilkan beberapa menit atau berjam -jam penelitian yang luas dan dalam waktu di internet dan menulis laporan komprehensif dengan baik -digunakan atas nama pengguna, dan Manus mengambil pendekatan yang berbeda.
itu Perusahaan baru saja mengumumkan “penelitian luas”, Fitur eksperimental baru yang memungkinkan pengguna untuk melakukan tugas dan ukuran besar dengan memanfaatkan kekuatan agen kecerdasan buatan paralel-bahkan lebih dari 100 pada satu waktu, semua fokus pada menyelesaikan satu tugas (atau serangkaian sub-tugas yang menyerahkan tujuan yang disebutkan di atas).
Sebelumnya dilaporkan bahwa ia menggunakan model Anthropor Claude untuk menjalankan platformnya.
AI Impact Series kembali ke San Francisco – 5 Agustus
Tahap selanjutnya dari kecerdasan buatan di sini – apakah Anda siap? Bergabunglah dengan para pemimpin dari Block, GSK dan SAP untuk mengambil tampilan eksklusif tentang cara memulai kembali agen independen dari tugas alur kerja yayasan-dari keputusan dalam waktu yang sebenarnya untuk otomatisasi komprehensif.
Mengamankan tempat Anda sekarang – ruang terbatas: https://bit.ly/3guPlf
Perawatan paralel untuk penelitian, ringkasan dan output kreatif
di dalam Video telah diposting di akun X resmiCo -founder Manus dan ilmuwan utama Yichao ‘Peak’ Ji menunjukkan penawaran eksperimental untuk penelitian ekstensif untuk membandingkan 100 sepatu olahraga.
Untuk menyelesaikan tugas, penelitian ekstensif berkisar di sekitar Manus segera 100 cabang simultan – yang masing -masing ditugaskan untuk menganalisis desain satu sepatu, harga dan ketersediaannya.
Hasilnya adalah matriks penyortiran yang dikirimkan di masing -masing spreadsheet dan halaman web dalam beberapa menit.
Perusahaan menyarankan bahwa penelitian ekstensif tidak terbatas pada analisis data. Ini juga dapat digunakan untuk tugas -tugas kreatif seperti menjelajahi desain.
Dalam salah satu skenario, agen manus dibuat secara bersamaan, desain stiker di 50 pola visual yang berbeda, dan aset olahan dalam file zip yang dapat diisi.
Menurut Manus, fleksibilitas ini berasal dari sistem di tingkat sistem untuk perawatan dan komunikasi paralel, agen.
Dalam video, Peak menjelaskan bahwa pencarian luas adalah aplikasi pertama untuk peningkatan simulasi virtual dan arsitektur yang mampu membatasi kapasitas akun 100 kali yang melebihi penawaran awal.
Fitur ini dirancang untuk diaktifkan secara otomatis selama tugas yang memerlukan analisis skala besar, tanpa sakelar manual atau konfigurasi yang diperlukan.
Ketersediaan dan harga
Penelitian luas tersedia dari pengguna di Manus Pro Plan dan akan tersedia secara bertahap bagi mereka yang dalam paket dasar dan dasar. Sampai sekarang, harga berlangganan manus telah diatur sebagai berikut sebulan.
- bebas – Ini termasuk $ 0 per bulan 300 pembaruan harian, akses ke mode obrolan, satu tugas simultan, dan satu tugas yang dijadwalkan.
- penting – Dolar bulanan akan menambah jam kredit 1900 (+1.900 bonus selama penawaran terbatas), 2 misi simultan dan terbarukan, akses ke model canggih dalam posisi agen, gambar/video/pembuatan video, dan sumber data eksklusif.
- plus – Ini melebihi 39 dolar per bulan hingga 3 tugas simultan dan 3 terjadwal, dan 3.900 jam kredit (+3.900 bonus), dan mencakup semua fitur dasar.
- Profesional -199 dolar/bulan menyediakan 10 tugas sinkron, 10 tugas terjadwal, 19.900 jam kredit (+19.900 bonus), akses awal ke fitur versi percobaan, kemeja manus, dan fitur lengkap fitur termasuk alat agen canggih dan pembuatan konten.
Ada juga diskon 17 % untuk harga ini untuk pengguna yang ingin membayar setiap tahun.
Peluncuran tergantung pada infrastruktur yang disajikan dengan Manus awal tahun ini, yang oleh perusahaan digambarkan bukan hanya agen Amnesty International, tetapi platform komputasi awan pribadi.
Setiap sesi manus bekerja pada perangkat virtual khusus, yang memungkinkan pengguna untuk mengakses akun cloud yang terorganisir melalui bahasa alami-persiapan yang dianggap perusahaan untuk memungkinkan alur kerja AI untuk tujuan umum.
Melalui penelitian yang luas, pengguna Manus dapat mendelegasikan penelitian atau eksplorasi kreatif di seluruh lusinan atau bahkan ratusan subkontraktor.
Tidak seperti sistem multi-agen tradisional dengan peran yang telah ditentukan sebelumnya (seperti manajer, programmer atau perancang), setiap sub-kelompok dalam penelitian luas adalah manus yang sepenuhnya mampu, bukan spesialis untuk pekerjaan peran tertentu secara mandiri dan mampu mengambil alih tugas umum apa pun.
Perusahaan mengatakan bahwa keputusan arsitektur ini membuka pintu bagi tugas -tugas yang fleksibel dan dikembangkan yang tidak terbatas pada template padat.
Apa manfaat dari penelitian mendalam?
Makna implisit tampaknya adalah bahwa operasi semua faktor ini secara paralel lebih cepat dan akan mengarah pada kelompok produk kerja yang lebih baik dan lebih bervariasi di luar laporan penelitian, tidak seperti faktor “penelitian mendalam” individu yang ditunjukkan oleh penyedia kecerdasan buatan lainnya atau ditawarkan.
Tetapi sementara Manus meningkatkan penelitian ekstensif sebagai penetrasi secara paralel dengan agen, perusahaan tidak memberikan bukti langsung bahwa melahirkan lusinan atau ratusan subkontraktor lebih efektif daripada memiliki tugas perawatan kapasitas tunggal secara berturut -turut.
Versi ini tidak termasuk kriteria kinerja, perbandingan, atau interpretasi teknis untuk membenarkan badan pendekatan ini-seperti meningkatkan penggunaan sumber daya, kompleksitas koordinasi, atau kekurangan potensial. Ini juga tidak memiliki detail tentang bagaimana internalis bekerja sama, bagaimana menggabungkan hasil, atau apakah sistem memberikan keuntungan yang terukur dalam kecepatan, akurasi atau biaya.
Akibatnya, sementara keuntungan menunjukkan ambisi arsitektur, manfaat praktisnya tetap pada metode yang lebih sederhana yang tidak terbukti berdasarkan informasi yang diberikan.
Sub -factor memiliki catatan campuran secara umum secara umum, sejauh ini …
Sementara implementasi penelitian Manus yang luas ditempatkan sebagai canggih dalam sistem agen kecerdasan buatan umum, ekosistem yang lebih luas telah menyaksikan hasil beragam dengan metode yang sama.
Misalnya, aktif Reddit, pengguna simbol Claude yang dijelaskan sendiri Ketakutan tentang simbolnya yang lambat dan mengonsumsi sejumlah besar simbol, dan memberikan visi terbatas untuk implementasi.
Titik nyeri umum termasuk kurangnya protokol koordinasi antara faktor -faktor, kesulitan dalam memperbaiki kesalahan, dan kinerja tidak teratur selama periode beban tinggi.
Tantangan -tantangan ini tidak selalu tercermin dalam implementasi Manus, tetapi mereka menyoroti kompleksitas pengembangan kerangka kerja multi -agen yang kuat.
Manus mengakui bahwa penelitian ekstensif masih eksperimental dan mungkin datang dengan beberapa pembatasan dengan pengembangan berkelanjutan.
Kami melihat ke depan
Dengan penelitian yang luas, Manus memperdalam komitmennya untuk mendefinisikan kembali bagaimana pengguna berinteraksi dengan agen kecerdasan buatan dalam skala besar.
Sementara platform lain bergulat dengan tantangan teknis dari koordinasi dan keandalan subagent, pendekatan manus mungkin merupakan ujian apakah agen agen-mengambil stereotip yang sempit dapat memenuhi visi kerja sama dan multi-utusan AI.
Perusahaan menyinggung ambisi yang lebih luas, menunjukkan bahwa infrastruktur di balik penelitian ekstensif meletakkan dasar untuk pertunjukan di masa depan. Pengguna dan adegan industri akan memperhatikan apakah gelombang baru dari struktur agen ini dapat naik ke tingkat kemampuannya – atau apakah tantangan yang terlihat di tempat lain di bidang kecerdasan buatan pada akhirnya akan diambil.
Koreksi: Artikel ini awalnya disebutkan secara tidak benar bahwa Manus berbasis di Cina ketika tidak; Dia ada di Singapura. Dia juga mengutip laporan sebelumnya bahwa mereka menggunakan model Alibaba Qwen; TIDAK. Kami telah memperbarui dan menyesali kesalahan.
Tautan sumber

baruAnda sekarang dapat mendengarkan Fox News!
Sebuah truk yang membawa hot dog berpartisipasi dalam kecelakaan di sepanjang negara bagian Pennsylvania, menyebabkan kekacauan penuh dengan hot dog yang tersebar di seberang jalan raya.
Seorang juru bicara kepolisian Pennsylvania mengatakan trailer traktor menghadapi beberapa masalah mekanis di sepanjang jalan raya ke -83 pada hari Jumat, utara garis negara bagian Maryland, menyebabkan kendaraan lain dihancurkan.
Kecelakaan itu menyebabkan pembersihan truk terhadap istirahat beton, menyebabkan trailer dibuka. Ketika ini terjadi, banyak hot dog yang tumpah dari truk.
Pisau turbin angin di lalu lintas di timur laut, jalan raya yang ramai
Kru penyelamat membersihkan truk hot dog yang bocor dari trailer traktor pada hari Jumat, di sepanjang jalan raya ke -83 di Shrewsbury, PA. (Perusahaan Pemadam Kebakaran Sukarelawan Shrewsbury Via AP)
“Setelah truk ini pergi dan menabrak jalan, ini adalah segalanya, dan suasananya masih sangat hangat,” kata Brad Dobirman, kepala Perusahaan Keunggulan Pemadam Kebakaran Shuzbury.
Para pejabat mengatakan empat orang dirawat karena cedera yang mengancam jiwa.
Ledakan truk ditangkap di kamera di lingkungan Chicago di pinggiran kota, sementara propana bocor untuk menyalahkan: pejabat

Seorang juru bicara kepolisian Pennsylvania mengatakan trailer traktor menghadapi beberapa masalah mekanis di sepanjang jalan raya ke -83. (Kepolisian Negara Bagian Pennsylvania)
Dobirman mengatakan dia belajar sesuatu tentang kecelakaan itu.
Klik di sini untuk mendapatkan aplikasi Fox News

Hot dog di atas kue yang ditutupi dengan mustard kuning. (ISTOCK)
“Aku bisa memberitahumu secara pribadi, bahwa hot dog sangat licin,” kata Dobirman. “Aku tidak tahu itu.”
Alexandra telah berkontribusi pada Digitter Associated Press dan Fox News untuk laporan ini.
Berita
Model visi cohere baru yang bekerja pada unit pemrosesan grafis, melampaui VLM kelas pertama atas tugas visual

Ingin lebih banyak visi yang cerdas dari kotak masuk Anda? Berlangganan buletin mingguan kami untuk mendapatkan apa yang hanya terkait dengan lembaga AI, data dan pemimpin keamanan. Berlangganan sekarang
Fitur penelitian mendalam yang tinggi dan analisis yang didukung kecerdasan buatan lainnya telah membuat lebih banyak model dan layanan yang ingin menyederhanakan proses ini dan membaca lebih banyak dokumen yang sudah digunakan perusahaan.
Perusahaan Kecerdasan Buatan Kanada berpadu Itu ditempatkan pada modelnya, termasuk model visual yang baru dirilis, untuk menunjukkan bahwa fitur pencarian yang dalam juga harus ditingkatkan untuk digunakan lembaga.
Perusahaan telah merilis perusahaan, model visual yang digunakan oleh institusi yang menargetkan, berdasarkan bagian belakang masalahnya. Perusahaan mengatakan bahwa model parameter adalah 112 miliar yang dapat “membuka visi data visual yang berharga, dan mengambil keputusan yang sangat akurat yang bergantung pada data dengan mengidentifikasi OCR dan analisis gambar,” kata perusahaan.
Perusahaan mengatakan: “Apakah itu menjelaskan buklet produk dengan rencana kompleks atau menganalisis gambar adegan dunia nyata untuk mendeteksi risiko, visi tersebut melebihi perlakuan tantangan yang paling menuntut bagi lembaga,” kata perusahaan itu. Di posting blog.
AI Impact Series kembali ke San Francisco – 5 Agustus
Tahap selanjutnya dari kecerdasan buatan di sini – apakah Anda siap? Bergabunglah dengan para pemimpin dari Block, GSK dan SAP untuk mengambil tampilan eksklusif tentang cara memulai kembali agen independen dari tugas alur kerja yayasan-dari keputusan dalam waktu yang sebenarnya untuk otomatisasi komprehensif.
Mengamankan tempat Anda sekarang – ruang terbatas: https://bit.ly/3guPlf
Ini berarti bahwa visi dapat membaca dan menganalisis jenis gambar yang paling umum yang dibutuhkan oleh lembaga: grafik, grafik, rencana, dokumen yang dipindai dan PDF.
Karena didasarkan pada perintah A, perintah A memerlukan melihat dua atau kurang dari unit pemrosesan grafis, seperti model teks. Model visi juga mempertahankan kemampuan teks pada A untuk membaca kata -kata pada gambar dan memahami setidaknya 23 bahasa. Cohere mengatakan bahwa, tidak seperti model lain, visi tersebut mengurangi total biaya kepemilikan lembaga dan sepenuhnya ditingkatkan untuk kasus pengambilan.
Bagaimana mengajarkan masalah ini
Cohere mengatakan itu mengikuti a Arsitektur LLAV Untuk membangun modelnya, termasuk model visual. Struktur ini mengubah fitur visual menjadi simbol penglihatan lembut, yang dapat dibagi menjadi ubin yang berbeda.
Perusahaan mengatakan bahwa ubin ini diteruskan ke menara teks, “parameter padat, 111b.” Dengan cara ini, satu gambar mengonsumsi hingga 3328 simbol. “
Kwaidle mengatakan bahwa ia melatih model visual dalam tiga tahap: menyelaraskan bahasa visi, subjek kontrol (SFT) dan belajar untuk memperkuat setelah pelatihan dengan komentar manusia (RLHF).
Perusahaan mengatakan: “Pendekatan ini memungkinkan penunjukan fitur enkripsi foto ke area yang mencakup model bahasa.” “Sebaliknya, selama tahap SFT, kami melatih yang dikodekan pada satu waktu, transformator penglihatan dan model bahasa pada berbagai tugas multimedia untuk pendidikan.”
Bayangkan AI
Tes standar menunjukkan bahwa visi melebihi model lain dengan kemampuan visual yang sama.
Colle Compet Command Vision Against OpenaiGPT 4.1, MatiHubungi 4 Mafrick, kesalahanPixtral besar dan salah 3 dalam sembilan tes standar. Perusahaan tidak menyebutkan apakah telah menguji model terhadap antarmuka pemrograman aplikasi mistral yang berfokus pada OCR, OCR Mistral.
Visi ini melampaui model lain dalam tes seperti ChartQA, Ocrbench, AI2D dan TextVQA. Secara umum, visibilitas mencapai 83,1 % dibandingkan dengan GPT 4.1 78,6 %, dan Llama 4 Maverkk 80,5 % dan 78,3 % dari Medium Mistral 3.
Sebagian besar model LLMS hari ini adalah multimedia, yang berarti mereka dapat membuat atau memahami media visual seperti gambar atau video. Namun, lembaga umumnya menggunakan lebih banyak dokumen grafis seperti grafik dan PDF, sehingga mengekstraksi informasi dari sumber data yang tidak terstruktur sering terbukti sulit.
Dengan penelitian yang mendalam di High, pentingnya membawa model yang mampu membaca dan menganalisis data yang tidak terorganisir dan bahkan mengunduhnya.
Cohere juga mengatakan bahwa mereka memberikan kepemimpinan dalam sistem bobot terbuka, berharap bahwa perusahaan yang ingin pindah dari model tertutup atau kepemilikan akan mulai menggunakan produk mereka. Sejauh ini, ada beberapa perhatian dari pengembang.
Tautan sumber

 Berita8 tahun ago
Berita8 tahun agoThese ’90s fashion trends are making a comeback in 2017
- Berita8 tahun ago
The final 6 ‘Game of Thrones’ episodes might feel like a full season
- Berita8 tahun ago
According to Dior Couture, this taboo fashion accessory is back
- Berita8 tahun ago
The old and New Edition cast comes together to perform
- Berita8 tahun ago
Phillies’ Aaron Altherr makes mind-boggling barehanded play
- Berita8 tahun ago
Uber and Lyft are finally available in all of New York State
- Berita8 tahun ago
Disney’s live-action Aladdin finally finds its stars
- Berita8 tahun ago
Mod turns ‘Counter-Strike’ into a ‘Tekken’ clone with fighting chickens

