
Berita
Para peneliti sedang mengembangkan kecerdasan buatan untuk membantu mendeteksi kanker payudara lobular yang sulit dideteksi
baruAnda sekarang dapat mendengarkan artikel Fox News!
Kecerdasan buatan memberikan pengaruh besar pada masa depan perawatan kanker.
Salah satu aplikasi terbaru dari teknologi ini adalah mengidentifikasi kanker payudara yang sulit dideteksi.
Para peneliti di Pusat Kanker Komprehensif Universitas Negeri Ohio – Institut Kanker Arthur G. James dan Institut Penelitian Richard J. Solove sedang mengembangkan kecerdasan buatan sebagai tahap awal untuk memprediksi pasien mana yang mungkin terkena kanker payudara lobular.
Wanita mengalahkan kanker otak yang mematikan dengan pengobatan sel induk eksperimental: ‘Sungguh menakjubkan’
Apa itu kanker payudara lobular?
Kanker payudara adalah kanker paling umum di kalangan wanita dan penyebab kematian akibat kanker nomor dua di negara ini.
Data menunjukkan bahwa kanker payudara lobular, yang agresif dan sulit dideteksi, menyumbang 10% hingga 15% dari diagnosis kanker payudara di Amerika Serikat.
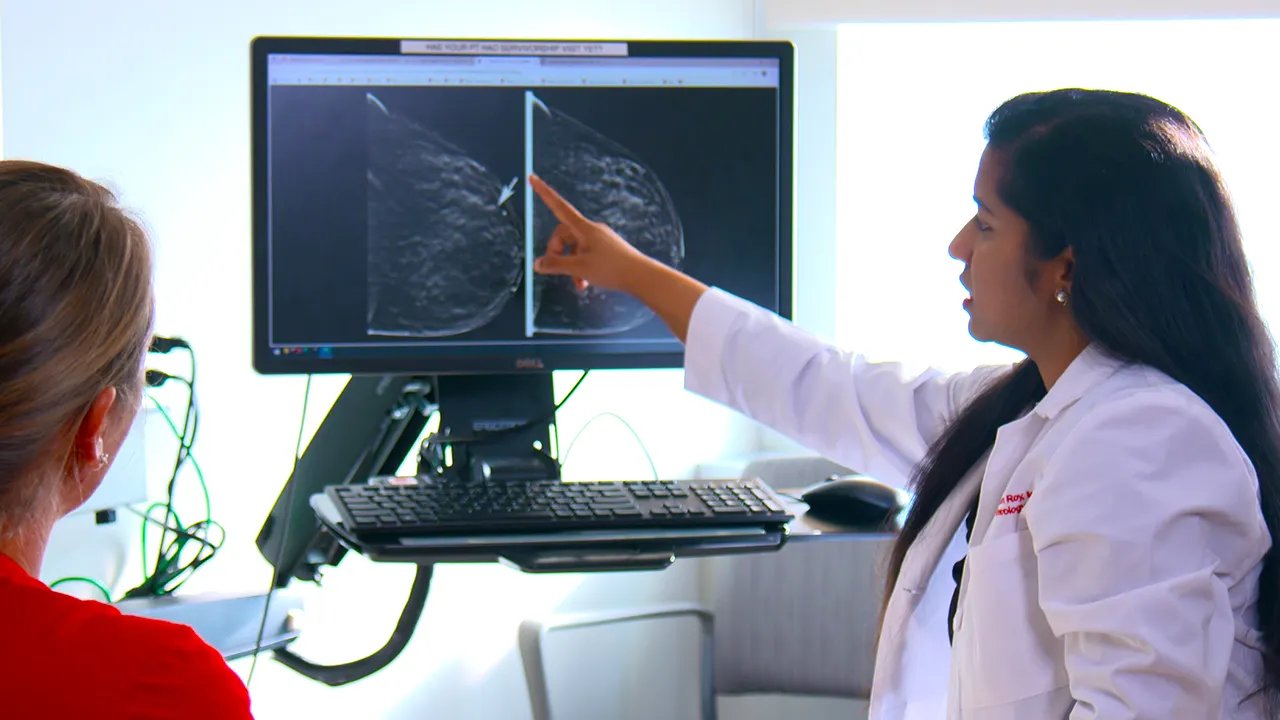
Beginilah tampilan kanker payudara lobular pada mammogram. Arya Roy, MD, melihat adanya kekeruhan pada pencitraan, yang membuatnya merekomendasikan pengujian tambahan. (Universitas Negeri Ohio)
Alih-alih berupa gumpalan sel yang membentuk tumor, karsinoma lobular tumbuh sebagai rangkaian sel yang panjang, sehingga tampak sebagai “ketebalan” pada mammogram. Artinya, penyakit ini mungkin sulit dideteksi sampai menyebar ke bagian tubuh lain, menurut Ohio State University.
Penyakit jenis ini juga berisiko kambuh bahkan 10 tahun setelah pasien sembuh dari kanker.
“Kami sangat membutuhkan alat yang lebih baik…yang dapat memprediksi pasien mana yang berisiko sangat tinggi.”
Selain itu, menurut Breast Imaging Society, sekitar 40% wanita di atas usia 40 tahun memiliki jaringan payudara yang padat, yang mungkin menimbulkan tantangan tambahan dalam mendeteksi dan meningkatkan risiko kanker payudara.
Meskipun karsinoma lobular invasif tumbuh, menyebar, dan merespons pengobatan secara berbeda dibandingkan karsinoma duktal invasif yang lebih umum, ahli onkologi masih mengikuti pedoman yang sama untuk kedua penyakit tersebut, menurut peneliti utama Dr. Arya Roy, spesialis kanker payudara di OSUCCC-James.
KLIK DI SINI UNTUK MENDAPATKAN APLIKASI FOX NEWS
“Tes genomik yang saat ini kami gunakan seringkali memberikan hasil yang tidak jelas atau bertentangan untuk karsinoma lobular, sehingga menyulitkan ahli onkologi untuk memutuskan pengobatan terbaik,” ujarnya dalam siaran pers. “Kami sangat membutuhkan alat yang lebih baik – khusus untuk karsinoma lobular – yang dapat memprediksi pasien mana yang benar-benar berisiko tinggi.”
Teknologi anti kanker
Roy kembali menegaskan betapa sulitnya mengidentifikasi kanker payudara lobular melalui pencitraan.
“Pada saat yang sama, sangat sulit untuk mengidentifikasi pasien yang berisiko lebih tinggi mengalami kekambuhan setelah pengobatan,” katanya kepada Fox News Digital. “Di sini kami menggunakan teknik kecerdasan buatan untuk mengidentifikasi pasien yang berisiko kambuhnya kanker ini.”

Arya Roy, MD, ditampilkan saat pemeriksaan skrining payudara, melihat salah satu bentuk kanker yang sering terlewatkan dalam pemeriksaan rutin. Ia menggunakan data dari kasus kanker payudara lobular aktual untuk melatih AI guna meningkatkan deteksi dini. (Universitas Negeri Ohio)
Dengan menggabungkan model AI dengan gambar patologi digital, dokter dapat mendeteksi biomarker dan indikator lain pada pasien kanker berisiko tinggi. Dikombinasikan dengan data klinis pasien, hasil ini digunakan untuk menciptakan sistem penilaian yang memprediksi kemungkinan kambuhnya kanker pada dekade berikutnya, kata para peneliti.
Alat AI saat ini sedang dalam pengembangan, dengan uji klinis dan penelitian yang didanai.
Klik di sini untuk berlangganan buletin kesehatan kami
“Kami berharap setelah alat AI ini dikembangkan sepenuhnya, yang akan membantu kami mengidentifikasi pasien yang berisiko kambuh, kami dapat menggunakannya untuk semua pasien penderita kanker payudara lobular,” lanjut Roy.
“Jika kita mengetahui bahwa seorang pasien memiliki peluang 10% lebih besar untuk kambuhnya kanker ini dalam waktu lima tahun, kita dapat terus memantau pasien tersebut.”
Peneliti studi mendorong perempuan untuk berdiskusi dengan dokter mereka apakah pencitraan tambahan tepat untuk mereka. (eStock)
Ahli onkologi juga dapat menggunakan teknik pencitraan lain untuk memastikan bahwa kanker tidak kambuh lagi pada pasien berisiko tinggi ini, Roy menambahkan, sambil mencatat bahwa metode baru berbasis AI ini dapat “memberikan harapan bagi banyak pasien.”
Ahli onkologi mendorong wanita untuk berdiskusi dengan dokternya apakah pencitraan tambahan sesuai untuk mereka.
Keterbatasan potensial
Harvey Castro, seorang dokter darurat dan pakar kecerdasan buatan di Texas, tidak terlibat dalam penelitian di Ohio State University tetapi mengomentari temuan tersebut untuk Fox News Digital.
Uji diri Anda dengan kuis gaya hidup terbaru kami
“Studi di Ohio State menunjukkan kemajuan penting dalam penggunaan AI untuk mendeteksi kanker payudara lobular, sebuah subtipe yang terkenal sulit, namun juga menyoroti hambatan yang masih menghalangi AI untuk sepenuhnya mencocokkan kompleksitas dunia nyata,” katanya.
Dokter menunjukkan bahwa salah satu masalah terbesar adalah melatih kecerdasan buatan pada data lama. “Kedokteran berkembang pesat, dan algoritme yang dibangun berdasarkan gambaran masa lalu mungkin tidak mengikuti pola masa kini, yang saya sebut penyimpangan temporal.”
“Sebelum alat-alat ini memasuki perawatan rutin, kita harus memastikan alat-alat tersebut diuji pada berbagai populasi di dunia nyata.”
Castro memperingatkan bahwa banyak sistem yang “berfungsi dengan baik” di laboratorium, namun mungkin gagal ketika diuji di rumah sakit atau kelompok pasien baru.
“Jaringan payudara yang padat tetap menjadi kelemahan AI,” katanya. “Kepadatan yang menyembunyikan tumor dari ahli radiologi juga dapat membingungkan algoritma, terutama di kalangan ras dan kelompok umur.”
Klik di sini untuk cerita kesehatan lainnya
Menurut Castro, AI tidak akan menggantikan ahli radiologi, melainkan mendefinisikan ulang cara kerjanya.
“Tetapi sebelum alat-alat ini memasuki perawatan rutin, kita harus memastikan alat-alat tersebut diuji pada beragam populasi di dunia nyata, tidak hanya pada data laboratorium yang ideal.”
Berita
Menyederhanakan tumpukan AI: Kunci kecerdasan seluler yang dapat diskalakan dari cloud hingga edge

Dikirim oleh Arm
Tumpukan perangkat lunak yang lebih sederhana adalah kunci AI yang portabel dan dapat diskalakan di seluruh cloud dan edge.
AI kini mendukung aplikasi dunia nyata, namun terhambat oleh tumpukan perangkat lunak yang terfragmentasi. Pengembang secara rutin memfaktorkan ulang model yang sama untuk target perangkat keras yang berbeda, sehingga membuang-buang waktu untuk menempelkan kode alih-alih mengirimkan fitur. Kabar baiknya adalah peralihan ini sedang berlangsung. Toolchain terpadu dan pustaka yang dioptimalkan memungkinkan model diterapkan di seluruh platform tanpa mengurangi performa.
Namun, masih ada satu kendala penting: kompleksitas perangkat lunak. Alat yang berbeda, peningkatan perangkat keras, dan tumpukan teknologi yang berlapis terus menghambat kemajuan. Untuk meluncurkan gelombang inovasi AI berikutnya, industri harus secara tegas beralih dari pengembangan yang tertutup ke arah platform yang lebih sederhana dan komprehensif.
Transformasi ini sudah mulai terbentuk. Penyedia cloud terkemuka, vendor platform edge, dan komunitas open source berkumpul dalam toolchain terpadu yang menyederhanakan pengembangan dan mempercepat penerapan, dari cloud hingga edge. Dalam artikel ini, kita akan mengeksplorasi mengapa penyederhanaan adalah kunci AI yang terukur, apa yang mendorong momentum ini, dan bagaimana platform generasi berikutnya mengubah visi ini menjadi hasil nyata.
Hambatannya: fragmentasi, kompleksitas, dan inefisiensi
Masalahnya tidak hanya terbatas pada variasi perangkat; Ini adalah upaya duplikat di seluruh kerangka kerja dan tujuan yang memperlambat waktu untuk menilai.
Sasaran perangkat lain-lain: GPU, NPU, perangkat khusus CPU, SoC seluler, dan akselerator khusus.
Segmentasi alat dan bingkai: TensorFlow, PyTorch, ONNX, MediaPipe, dan lainnya.
Pembatasan tepi: Perangkat memerlukan kinerja hemat energi secara real-time dan dengan beban minimal.
menurut Penelitian GartnerNamun, ketidaksesuaian ini menimbulkan rintangan besar: lebih dari 60% inisiatif AI terhenti sebelum produksi, didorong oleh kompleksitas integrasi dan variabilitas kinerja.
Seperti apa penyederhanaan perangkat lunak?
Penyederhanaan mengelompokkan sekitar lima langkah yang mengurangi biaya dan risiko rekayasa ulang:
Lapisan abstraksi lintas platform Yang mengurangi rekayasa ulang saat mentransfer model.
Pustaka penyetelan kinerja Ini diintegrasikan ke dalam kerangka pembelajaran mesin utama.
Desain arsitektur terpadu Mulai dari pusat data hingga seluler.
Standar terbuka dan runtime (misalnya ONNX, MLIR) yang mengurangi penguncian dan meningkatkan kompatibilitas.
Ekosistem pengembang terlebih dahulu Dengan penekanan pada kecepatan, reproduktifitas, dan skalabilitas.
Pergeseran ini membuat AI lebih mudah diakses, terutama bagi startup dan tim akademis yang sebelumnya tidak memiliki sumber daya untuk optimasi kustom. Proyek seperti standar Optimum dan MLPerf Hugging Face juga membantu menstandardisasi dan memvalidasi kinerja di seluruh perangkat.
Momentum ekosistem dan sinyal dunia nyata Penyederhanaan bukan lagi sebuah aspirasi; Itu sedang terjadi sekarang. Di seluruh industri, pertimbangan perangkat lunak memengaruhi keputusan pada tingkat IP dan desain silikon, sehingga menghasilkan solusi siap produksi sejak hari pertama. Para pemain kunci dalam ekosistem mendorong transformasi ini dengan menyelaraskan upaya pengembangan perangkat keras dan perangkat lunak, sehingga memberikan integrasi yang lebih erat di seluruh grup.
Katalis utamanya adalah peningkatan pesat dalam inferensi di edge, di mana model AI diterapkan langsung di perangkat, bukan di cloud. Hal ini telah meningkatkan permintaan akan paket perangkat lunak sederhana yang mendukung optimalisasi end-to-end, mulai dari silikon, sistem, hingga aplikasi. Perusahaan seperti Arm meresponsnya dengan memungkinkan penggabungan yang lebih erat antara platform komputasi dan rangkaian alat perangkat lunak mereka, sehingga membantu pengembang mempercepat waktu penerapan tanpa mengorbankan kinerja atau portabilitas. Munculnya model yayasan multimodal dan tujuan umum (seperti LLaMA, Gemini, Claude) juga meningkatkan urgensinya. Model-model ini memerlukan runtime fleksibel yang dapat diskalakan di lingkungan cloud dan edge. Agen AI, yang berinteraksi, beradaptasi, dan melakukan tugas secara mandiri, meningkatkan kebutuhan akan perangkat lunak lintas platform yang sangat efisien.
MLPerf Inference versi 3.1 mencakup lebih dari 13.500 hasil kinerja dari 26 penyedia, memvalidasi benchmarking lintas platform untuk beban kerja AI. Hasilnya mencakup pusat data dan perangkat edge, menunjukkan keragaman penerapan optimal yang kini sedang diuji dan dibagikan.
Secara keseluruhan, sinyal-sinyal ini menunjukkan bahwa permintaan dan insentif pasar berkisar pada serangkaian prioritas yang sama, termasuk memaksimalkan kinerja per watt, memastikan portabilitas, meminimalkan latensi, dan memberikan keamanan dan konsistensi dalam skala besar.
Apa yang perlu dilakukan agar penyederhanaan berhasil
Untuk mewujudkan potensi platform AI yang disederhanakan, beberapa hal harus dilakukan:
Desain bersama perangkat keras/perangkat lunak yang kuat: Fitur perangkat keras yang diekspos dalam kerangka perangkat lunak (misalnya, pengali matriks dan instruksi akselerator) dan, sebaliknya, perangkat lunak yang dirancang untuk memanfaatkan perangkat keras yang mendasarinya.
Toolchain dan perpustakaan yang konsisten dan kuat: Pengembang memerlukan perpustakaan yang andal dan terdokumentasi dengan baik yang berfungsi di seluruh perangkat. Portabilitas kinerja hanya berguna jika alatnya stabil dan didukung dengan baik.
Ekosistem terbuka: Vendor perangkat keras, pengelola kerangka perangkat lunak, dan pengembang model harus berkolaborasi. Standar dan proyek umum membantu menghindari penemuan kembali roda untuk setiap perangkat atau kasus penggunaan baru.
Abstraksi yang tidak mengaburkan kinerja: Meskipun abstraksi tingkat tinggi membantu pengembang, mereka tetap harus memungkinkan penyesuaian atau visibilitas bila diperlukan. Keseimbangan yang tepat antara abstraksi dan kontrol adalah kuncinya.
Keamanan, privasi, dan kepercayaan tertanam di dalamnya: Terutama karena semakin banyak komputasi yang beralih ke perangkat (edge/mobile), isu-isu seperti perlindungan data, eksekusi yang aman, keamanan model, dan privasi menjadi penting.
ARM sebagai contoh penyederhanaan yang didorong oleh ekosistem
Penyederhanaan AI dalam skala besar kini bergantung pada desain tingkat sistem, di mana silikon, perangkat lunak, dan alat pengembang berkembang secara bersamaan. Pendekatan ini memungkinkan beban kerja AI berjalan secara efisien di berbagai lingkungan, mulai dari kluster inferensi cloud hingga perangkat edge dengan baterai terbatas. Hal ini juga mengurangi biaya pengoptimalan kustom, sehingga lebih mudah menghadirkan produk baru ke pasar dengan lebih cepat. Arm (Nasdaq:Arm) memajukan model ini dengan berfokus pada platform yang mendorong peningkatan perangkat lunak dan perangkat keras melalui tumpukan perangkat lunak. di dalam Komputasi 2025Arm menjelaskan bagaimana CPU Arm9 terbaru, bersama dengan ekstensi AI ISA dan perpustakaan Kleidi, memungkinkan integrasi yang lebih erat dengan kerangka kerja yang banyak digunakan seperti PyTorch, ExecuTorch, ONNX Runtime, dan MediaPipe. Penyelarasan ini mengurangi kebutuhan akan kernel khusus atau driver yang disetel secara manual, sehingga memungkinkan pengembang untuk meningkatkan kinerja perangkat keras tanpa meninggalkan rantai alat yang sudah dikenal.
Implikasinya pada dunia nyata sangatlah signifikan. Di pusat data, platform berbasis Arm memberikan peningkatan kinerja per watt, yang sangat penting untuk menskalakan beban kerja AI secara berkelanjutan. Pada perangkat konsumen, peningkatan ini memungkinkan pengalaman pengguna yang sangat responsif dan kecerdasan latar belakang yang selalu aktif namun hemat daya.
Secara lebih luas, industri ini mengandalkan penyederhanaan sebagai keharusan desain, mengintegrasikan dukungan AI langsung ke dalam peta jalan perangkat keras, meningkatkan portabilitas perangkat lunak, dan menstandardisasi dukungan untuk runtime AI umum. Pendekatan Arm menunjukkan bagaimana integrasi mendalam di seluruh tumpukan komputasi dapat menjadikan AI yang dapat diskalakan menjadi kenyataan praktis.
Validasi pasar dan momentum
Pada tahun 2025, Hampir setengah dari komputasi yang dikirimkan ke hyperscaler teratas akan berjalan pada arsitektur berbasis Armsebuah tonggak sejarah yang menegaskan transformasi besar dalam infrastruktur cloud. Ketika beban kerja AI menjadi lebih intensif sumber daya, penyedia cloud memprioritaskan arsitektur yang memberikan kinerja per watt yang unggul dan mendukung portabilitas perangkat lunak yang lancar. Perkembangan ini mewakili poros strategis menuju infrastruktur hemat energi dan terukur yang dioptimalkan untuk kinerja dan kebutuhan AI modern.
Pada bagian edge, mesin inferensi yang kompatibel dengan Arm memungkinkan pengalaman real-time, seperti terjemahan langsung dan asisten suara yang selalu aktif, pada perangkat bertenaga baterai. Kemajuan ini menghadirkan kemampuan AI yang kuat secara langsung kepada pengguna, tanpa mengorbankan efisiensi energi.
Momentum pengembang juga semakin cepat. Dalam kolaborasi baru-baru ini, GitHub dan Arm menyediakan driver asli untuk Arm Linux dan Windows untuk GitHub Actions, sehingga menyederhanakan alur kerja CI untuk platform berbasis Arm. Alat-alat ini menurunkan hambatan masuk bagi pengembang dan memungkinkan pengembangan lintas platform yang lebih efisien dalam skala besar.
Apa yang terjadi selanjutnya?
Menyederhanakan tidak berarti menghilangkan kompleksitas sepenuhnya; Artinya mengelolanya dengan cara yang memungkinkan inovasi. Saat tumpukan AI menjadi stabil, pemenangnya adalah mereka yang memberikan kinerja mulus di lanskap yang terfragmentasi.
Dari perspektif masa depan, harapkan:
Standar sebagai pagar pembatas: Kombinasi MLPerf + OSS memandu Anda untuk melakukan peningkatan selanjutnya.
Lebih ke hulu, lebih sedikit percabangan: Fitur perangkat keras ada di alat utama, bukan di cabang khusus.
Konvergensi penelitian dan produksi: Pengiriman lebih cepat dari kertas ke produk melalui waktu proses bersama.
kesimpulan
Fase AI selanjutnya bukanlah tentang perangkat eksotik; Ini juga tentang perangkat lunak yang bertransisi dengan baik. Ketika model yang sama menjangkau cloud, klien, dan edge secara efisien, tim melakukan pengiriman lebih cepat dan menghabiskan lebih sedikit waktu untuk membangun kembali tumpukan.
Penyederhanaan ekosistem secara keseluruhan, bukan logo yang dipimpin oleh merek, yang akan memisahkan para pemenang. Aturan praktis permainannya jelas: standarisasi platform, peningkatan hulu, dan pengukuran menggunakan standar terbuka. Pelajari cara kerja platform perangkat lunak Arm AI Kami mewujudkan masa depan ini – secara efisien, aman, dan dalam skala besar.
Artikel bersponsor adalah konten yang diproduksi oleh perusahaan yang membayar postingan tersebut atau memiliki hubungan kerja dengan VentureBeat, dan selalu diberi label dengan jelas. Untuk informasi lebih lanjut, hubungi penjualan@venturebeat.com.
Berita
Analisis tersebut menemukan adanya penurunan tajam dalam jumlah generasi muda yang mengidentifikasi diri sebagai transgender dan non-biner
baruAnda sekarang dapat mendengarkan artikel Fox News!
Semakin banyak data yang mendukung penurunan tajam jumlah orang dewasa muda yang mengidentifikasi diri mereka sebagai transgender atau non-biner.
Pekan lalu, Fox News Digital melaporkan data yang dibagikan oleh Eric Kaufman, seorang profesor politik di Universitas Buckingham, yang menunjukkan bahwa persentase mahasiswa yang mengidentifikasi diri selain laki-laki atau perempuan telah berkurang setengahnya hanya dalam dua tahun.
Kini, Jan Twenge, seorang profesor psikologi di San Diego State University, telah mengidentifikasi data tambahan yang tampaknya mengkonfirmasi temuan tersebut secara lebih luas.
Sebuah analisis baru menemukan bahwa “tren” transgender menurun tajam di kampus-kampus Amerika
Pertama, Twenge menganalisis data dari Survei Nadi Rumah Tangga yang representatif secara nasional, yang menanyakan masyarakat secara langsung tentang identifikasi mereka sebagai transgender, ia melaporkan dalam sebuah artikel untuk majalah tersebut. Teknologi generasi.
“Data Pulsa Rumah Tangga menunjukkan penurunan ID untuk kelompok usia 18 hingga 22 tahun pada tahun 2024, namun saya berhati-hati dalam menarik kesimpulan dari data tersebut, karena penurunan tersebut hanya terjadi dalam jangka waktu terbatas (Juli hingga September 2024) — dan dua dari tiga lembaga survei menambahkan opsi identifikasi non-biner yang belum pernah ada sebelumnya,” tulisnya. “Mungkin inilah alasan mengapa definisi transgender ditolak.”
Semakin banyak data yang mendukung penurunan tajam jumlah orang dewasa muda yang mengidentifikasi diri mereka sebagai transgender atau non-biner. (I stok)
Selanjutnya, profesor tersebut – yang juga penulis Generations: The Real Differences Between Generation Z, Millennials, Generation X, Boomers, and Silents – mengamati survei lain yang representatif secara nasional.
Collaborative Election Study (CES), sebuah survei non-probabilitas yang dikirimkan setiap tahun pada musim gugur oleh YouGov dan dikelola oleh Universitas Tufts, menanyakan tentang identifikasi transgender di antara semua orang dewasa di Amerika Serikat dari tahun 2021 hingga 2024. Survei ini juga mencakup pertanyaan terpisah tentang identifikasi sebagai non-biner.
Studi: Operasi sementara meningkatkan risiko kondisi kesehatan mental dan pikiran untuk bunuh diri
Pada tahun 2021, 2022, dan 2024, CES bertanya: “Apakah Anda mengidentifikasi diri Anda sebagai transgender?” Pilihannya adalah “ya”, “tidak”, dan “Saya memilih untuk tidak mengatakannya”.
Tanggapan “Saya lebih suka tidak mengatakan” dianggap sebagai data yang hilang, Twenge berbagi dengan Fox News Digital.
Mulai tahun 2021, pertanyaan jenis kelamin/gender di CES: “Apa gender Anda?” Dengan pilihan “Pria”, “Wanita”, “Non-biner” dan “Lainnya”.

Mulai tahun 2021, pertanyaan jenis kelamin/gender di CES: “Apa gender Anda?” Dengan pilihan “Pria”, “Wanita”, “Non-biner” dan “Lainnya”. (Koleksi Smith/Gado/Getty Images)
Di antara kelompok usia 18 hingga 22 tahun, identifikasi trans turun hampir setengahnya pada tahun 2022 hingga 2024 — dan identifikasi non-biner turun lebih dari setengahnya antara tahun 2023 dan 2024.
“Ketika saya mengamati orang dewasa dari segala usia dalam survei… Saya menemukan peningkatan yang signifikan dalam identifikasi transgender dari mereka yang lahir sebelum tahun 1980 (Generasi
“Identifikasi transgender kemudian menurun, terutama bagi mereka yang lahir pada tahun 2005 dan 2006 (yang kini berusia antara 18 dan 20 tahun).”
“Saya pikir pertanyaannya sekarang bukanlah apakah jumlah transgender mengalami penurunan, tapi sejauh mana.”
Ada beberapa teori mengapa hal ini terjadi.
“Salah satu kemungkinannya adalah adanya perubahan dalam penerimaan; seiring dengan meningkatnya penerimaan, semakin banyak remaja yang diidentifikasi sebagai transgender dan/atau bersedia untuk mengidentifikasi sebagai transgender dalam survei tersebut,” kata Twenge. “Ketika penerimaan terhadap transgender menurun, identifikasi transgender (atau setidaknya identifikasi transgender dalam survei) menurun.”

Di antara kelompok usia 18 hingga 22 tahun, identifikasi trans turun hampir setengahnya pada tahun 2022 hingga 2024 — dan identifikasi non-biner turun lebih dari setengahnya antara tahun 2023 dan 2024. (I stok)
Dalam analisis sebelumnya yang melihat data dari survei lain, Twenge menemukan bahwa peningkatan identifikasi transgender antara tahun 2014 dan 2023 tidak mencakup orang yang berusia di atas 45 tahun (Generasi X dan Baby Boomers).
“Hal ini membuat kecil kemungkinan bahwa perubahan tersebut disebabkan oleh penerimaan, yang seharusnya mempengaruhi orang-orang dari segala usia,” katanya. “Namun, ada kemungkinan penerimaan meningkat lebih lanjut di kalangan generasi muda antara tahun 2014 dan 2023 dan kemudian semakin menurun pada tahun 2024.”
Twenge menegaskan, mengidentifikasi sebagai transgender dan mengidentifikasi sebagai non-biner adalah dua hal yang berbeda.
KLIK DI SINI UNTUK MENDAPATKAN APLIKASI FOX NEWS
“Salah satu alasan saya melakukan analisis ini adalah karena survei yang digunakan Profesor Kaufman tidak menanyakan tentang identifikasi diri sebagai transgender – survei tersebut menanyakan tentang identifikasi diri sebagai non-biner atau apa pun selain laki-laki atau perempuan,” katanya. “Saya ingin melihat apakah ada penurunan identifikasi transgender.”
“Saya juga berpendapat penting untuk melihat sampel yang mewakili secara nasional dan bukan hanya siswa dari sekolah elit,” tambahnya.
Seorang pakar kesehatan mental mengatakan, ”Setelah seseorang merasa lebih nyaman dengan identitasnya, mereka tidak lagi perlu mendefinisikan diri secara ketat.” (Istock)
Kaufman memuji laporan baru Twenge sebagai “yang terbaik di bidangnya.”
“Senang sekali melihat para peneliti dari generasi akademis mainstream bisa mengejar ketinggalan,” katanya kepada Fox News Digital. “Datanya sangat memperkuat apa yang saya temukan dengan menggunakan data FIRE, Brown, dan Andover Phillips.”
Klik di sini untuk berlangganan buletin kesehatan kami
“Saya pikir pertanyaannya sekarang bukan itu jika Dia menambahkan: “Jumlah transgender mengalami penurunan, namun seberapa jauh jumlah mereka akan menurun – dan apa dampaknya terhadap proyek progresif budaya, serta tren dalam pembedahan dan diagnosis interseks.”
“Mungkin generasi muda akan menyadari bahwa mereka tidak perlu mengumumkan atau melabeli segala sesuatu tentang diri mereka untuk menjadi baik.”
Jonathan Alpert, seorang psikoterapis di New York City, mengatakan perubahan ini kemungkinan besar merupakan “koreksi alami”.
“Untuk sementara waktu, kami mengajari generasi muda untuk menafsirkan secara berlebihan setiap perasaan. Budaya pengobatan mengatakan kepada mereka bahwa setiap ketidaknyamanan memerlukan label atau diagnosis,” Alpert, yang tidak ikut serta dalam survei tersebut, sebelumnya mengatakan kepada Fox News Digital. “Bagi sebagian orang, label ini telah menjadi ‘non-biner’ – tidak mengidentifikasi gender.”
Alih-alih menyangkal identitas mereka, Albert berkata: Anak muda Dia mungkin hanya bosan merasa tertekan untuk mengidentifikasi setiap emosi atau perbedaan dengan identitas baru.
Uji diri Anda dengan kuis gaya hidup terbaru kami
“Jadi, pada dasarnya, kinerjalah yang melambat – setidaknya seperti yang ditunjukkan oleh penelitian ini,” katanya. “Beberapa tahun yang lalu, identitas diperlakukan hampir seperti lencana sosial. Sekarang, mungkin kaum muda menyadari bahwa mereka tidak perlu mengiklankan atau memberi label segala sesuatu tentang diri mereka agar menjadi valid.”
Albert mengatakan dia melihat pola yang sama dalam dirinya Praktek terapi.
Klik di sini untuk cerita kesehatan lainnya
“Saat orang merasa lebih nyaman dengan identitas mereka, mereka tidak lagi perlu mendefinisikan diri mereka secara kaku. Bagi saya, ini adalah tanda tumbuhnya rasa percaya diri, bukan fanatisme.”
Fox News Digital telah menghubungi Universitas Tufts dan Biro Sensus AS untuk meminta komentar.

Para peneliti di Mila telah mengusulkan teknik baru yang membuat model linguistik besar (LLM) jauh lebih efisien ketika melakukan inferensi kompleks. Bernama pemikiran Markovian,Pendekatan ini memungkinkan LLM untuk terlibat dalam penalaran yang berkepanjangan tanpa menimbulkan biaya komputasi yang mahal yang saat ini membatasi tugas-tugas tersebut.
Implementasi tim, sebuah lingkungan yang disebut Delethink, membangun rantai inferensi menjadi potongan-potongan berukuran tetap, memecahkan masalah penskalaan yang mengganggu respons LLM yang sangat panjang. Perkiraan awal menunjukkan bahwa untuk model parameter 1,5 miliar, metode ini dapat mengurangi biaya pelatihan lebih dari dua pertiga dibandingkan pendekatan standar.
Kutukan kuadrat dari inferensi string panjang
Agar LLM dapat memecahkan masalah yang kompleks, Anda sering kali perlu membuat rantai panjang token “berpikir” perantara, yang sering disebut sebagai rantai penalaran (CoT). Dalam beberapa tahun terakhir, para peneliti telah menemukan bahwa penggunaan… Pembelajaran penguatan (RL) untuk melatih model guna menghasilkan CoT yang lebih panjang (terkadang disebut sebagai LongCoT) yang sangat meningkatkan kemampuan penalaran mereka.
Namun, cara standar untuk melakukan hal ini memiliki kelemahan serius: kecerdasan buatan "negara" (Vektor ditambah semua kode logika yang dihasilkan sejauh ini dalam pemrosesannya) bertambah seiring dengan setiap kode logika baru. Untuk berbicara Model berbasis transformatorArtinya, biaya komputasi akan melonjak secara kuadrat seiring bertambahnya panjang rantai penalaran, sehingga menjadi sangat mahal untuk melatih model pada tugas-tugas yang sangat kompleks.
Sebagian besar upaya saat ini untuk mengelola biaya ini berfokus pada membatasi jumlah pemikiran yang dilakukan model, yang secara implisit lebih memilih solusi yang lebih singkat atau mengakhiri proses lebih awal. Meskipun metode ini memberikan sedikit bantuan, para peneliti MILAA masih bekerja dalam kerangka LongCoT dan oleh karena itu pada dasarnya berkomitmen pada sifat kuadratnya.
Daripada mencoba mengendalikan pertumbuhan aritmatika, Mila menciptakan lingkungan RL yang menghindari masalah kuadrat sama sekali. Seperti yang dijelaskan oleh rekan penulis Amir Hossein Kazeminejad, tujuannya adalah untuk mengaktifkan kemampuan seperti berpikir multi-minggu dan penemuan ilmiah. "Sistem ini (dan RL yang diperlukan untuk mengaktifkan kemampuan tersebut) tidak didukung oleh model LongCoT saat ini, karena biaya komputasi kuadrat," Dia berkata.
Pikirkan sebagian dengan Delethink
Solusi yang ditemukan para peneliti adalah model yang mereka sebut "pemikir Markovian" Model ini beralasan sambil menjaga ukuran jendela konteks inferensinya tetap konstan. Ide dasarnya adalah mengubah pengaturan RL kelas "Berapa lama model berpikir?" dari "Jumlah konteks yang perlu diproses." Jika dilakukan dengan benar, pemikir Markovian akan mengubah masalah pertumbuhan kuadrat menjadi komputasi linier dan kebutuhan memori konstan untuk inferensi LLM.
Para peneliti mempraktikkan model ini melalui Delethink, yang memaksa model untuk mempertimbangkan serangkaian potongan berukuran tetap, seperti 8,000 token sekaligus. Dalam setiap bagian, model membuat kesimpulan seperti biasanya, menggunakan mekanisme perhatian klasik. Namun ketika mencapai potongan maksimum, lingkungan akan mengatur ulang konteksnya, membuat prompt baru yang menyertakan kueri asli ditambah permintaan singkat "meneruskan" Dari bagian sebelumnya. Misalnya, relai dapat berupa beberapa kode terakhir dari bagian CoT sebelumnya atau ringkasan hasil yang paling penting.
Penataan ulang masalah ini memaksa model untuk belajar bagaimana memasukkan ringkasan kemajuannya, atau "keadaan Markovian tekstual," Pada tahap ini terus memikirkan bagian selanjutnya. Hal ini mengatasi kekhawatiran umum mengenai apakah model dapat mengingat detail penting dari langkah sebelumnya.
Menurut Kazemnejad, model mempelajari apa yang harus diingatnya. "Dengan pelatihan…model dipaksa untuk belajar bagaimana melanjutkan dalam situasi kritis," Dia menjelaskan. Dia menambahkan klarifikasi penting untuk penggunaan praktis: vektor masukan asli, termasuk dokumen atau data kontekstual yang ditambahkan ke dalamnya, tidak diubah. “Pendekatan kami menargetkan fase inferensi dan tidak mengubah vektor." Dia berkata.
Hapus pemikiran tentang pekerjaan
Untuk menguji pendekatan mereka, para peneliti melatih R1-Distill-1.5B dengan Delethink pada kumpulan data soal matematika tingkat kompetisi, kemudian mengevaluasinya berdasarkan beberapa tolok ukur. Model ini dilatih untuk mempertimbangkan hingga 24.000 token tetapi dengan batas tetap sebesar 8.000 token.
Peneliti Bandingkan ini dengan model yang dilatih menggunakan metode LongCoT-RL standar. Temuan mereka menunjukkan bahwa model yang dilatih dengan Delethink dapat menganalisis hingga 24,000 token, menyamai atau melampaui model LongCoT yang dilatih dengan anggaran yang sama yaitu 24,000 token berdasarkan standar matematika. Dalam tugas lain seperti pertanyaan tingkat pemrograman dan PhD, Delethink juga menyamai atau sedikit mengalahkan LongCoT. “Secara keseluruhan, hasil ini menunjukkan bahwa Delethink menggunakan kode penalarannya seefektif LongCoT-RL dengan pengurangan komputasi,” tulis para peneliti.
Manfaatnya menjadi lebih nyata ketika anggaran pelatihan diperluas. Meskipun model yang dilatih dengan LongCoT dengan cepat mencapai batas pelatihannya, model yang dilatih dengan Delethink terus meningkatkan performanya. Misalnya, beberapa masalah matematika tidak dapat diselesaikan hingga model tersebut menguraikan hingga 140.000 simbol, jauh melebihi anggaran pelatihan sebesar 24.000 simbol. Fitur komputasi linier ini sangat bagus untuk aplikasi perusahaan. Para peneliti memperkirakan bahwa melatih model dengan panjang pemikiran rata-rata 96.000 simbol akan memerlukan 27 bulan H100-GPU dengan LongCoT, dibandingkan hanya 7 bulan dengan Delethink.
Efisiensi ini meluas langsung ke inferensi, yang merupakan biaya operasional utama bagi sebagian besar organisasi. "Model yang dilatih dengan penalaran Markovian menggunakan heuristik yang sama (hapus pelacakan) selama waktu pengujian, yang memberikan manfaat yang sama dari aritmatika linier dan memori persisten setelah pelatihan." kata Kazemnejad. Dia memberikan contoh praktis: agen AI bisa melakukan hal itu "Debug basis kode yang besar dan pikirkan untuk waktu yang lama…yang tentu saja mengurangi biaya secara signifikan dibandingkan dengan pendekatan LongCoT tradisional."
Menariknya, para peneliti menemukan bahwa model inferensi yang sudah jadi, bahkan tanpa pelatihan khusus apa pun, memang menunjukkan kemampuan bernalar dengan cara Markovian. Temuan ini mempunyai implikasi praktis langsung bagi pengembang. "Dalam praktiknya, ini berarti – tanpa Delethink-RL – model ini benar-benar dapat menjalankan lingkup pelacakan delethink dan bekerja secara kompetitif dengan LongCoT pada tugas benchmark kami," kata Kazemnejad.
Pengalaman mereka dengan model yang lebih besar seperti GPT-OSS 120B Tunjukkan kinerja yang kuat dengan Delethink di berbagai tugas kompleks. Kemampuan bawaan ini memberikan titik awal yang kuat untuk pelatihan RL, yang membantu menjelaskan mengapa metode ini sangat efektif. “Secara keseluruhan, hasil ini menunjukkan bahwa Delethink kompatibel dan konsisten dengan model tercanggih,” para peneliti menyimpulkan.
Keberhasilan pemikiran Markovian menunjukkan bahwa hal ini mungkin dilakukan "Model berpikir generasi penerus untuk berpikir dalam jutaan simbol," Catatan peneliti. Hal ini membuka pintu bagi kemampuan AI yang secara fundamental baru, melampaui keterbatasan yang ada saat ini.
"Pemikiran Markovian…membuka jalan bagi model-model yang dapat “berpikir” dalam jangka waktu yang sangat panjang, yang kami anggap sebagai langkah penting menuju penemuan ilmiah pada akhirnya," kata Kazemnejad. "Pendekatan kami menghilangkan hambatan besar dan memungkinkan pelatihan untuk misi jangka panjang, sehingga memungkinkan kemampuan generasi berikutnya."

 Berita8 tahun ago
Berita8 tahun agoThese ’90s fashion trends are making a comeback in 2017
- Berita8 tahun ago
The final 6 ‘Game of Thrones’ episodes might feel like a full season
- Berita8 tahun ago
According to Dior Couture, this taboo fashion accessory is back
- Berita8 tahun ago
Uber and Lyft are finally available in all of New York State
- Berita8 tahun ago
The old and New Edition cast comes together to perform
- Berita8 tahun ago
Phillies’ Aaron Altherr makes mind-boggling barehanded play

 Bisnis8 bulan ago
Bisnis8 bulan agoMeta Sensoren Disensi Internal atas Ban Trump Mark Zuckerberg
- Berita8 tahun ago
New Season 8 Walking Dead trailer flashes forward in time


