
Berita
Pertempuran untuk AI-Cenable di web: NLWB dan apa yang perlu diketahui lembaga

Bergabunglah dengan buletin harian dan mingguan untuk mendapatkan pembaruan terbaru dan konten eksklusif untuk meliput kecerdasan buatan terkemuka di industri ini. Pelajari lebih lanjut
Pada generasi pertama web, pada akhir 1990 -an, pencariannya baik -baik saja tetapi tidak hebat, dan tidak mudah untuk menemukan banyak hal. Hal ini menyebabkan munculnya protokol sindikasi pada awal dekade pertama abad kedua puluh, di mana atom dan RSS (penyederhanaan) menyediakan cara yang lebih sederhana bagi situs web untuk menjadi berita utama dan konten lainnya dengan mudah tersedia dan dicari.
Di era modern kecerdasan buatan, sekelompok protokol baru tampaknya melayani tujuan dasar yang sama. Kali ini, alih -alih memfasilitasi situs bagi manusia untuk menemukannya, datang ke segalanya untuk membuat situs web lebih mudah bagi Amnesty International. priaProtokol Kontrol Bentuk (MCP), GoogleAgent2agen 2AGE dan Model Bahasa Besar/ LLMS.TX adalah di antara upaya saat ini.
Protokol terbaru adalah tegangan NLWB (Microsoft Natural Language), yang diumumkan selama konferensi Build 2025. NLWB juga secara langsung ditautkan dengan generasi pertama standar berbagi web, seperti yang divisualisasikan dan dibuat oleh RV Guha, yang membantu menciptakan RSS dan RDF (Framework Deskripsi Sumber Daya) dan Schema.org.
NLWB memungkinkan situs web untuk menambahkan antarmuka percakapan yang mudah dioperasikan, yang secara efektif mengubah situs web apa pun menjadi aplikasi AI di mana pengguna dapat menanyakan tentang konten menggunakan bahasa alami. NLWB tidak harus terkait dengan persaingan dengan protokol lain; Sebaliknya, itu dibangun di atas mereka. Protokol baru menggunakan format data terstruktur saat ini seperti RSS, dan setiap mitra NLWB berfungsi sebagai server MCP.
“Gagasan di balik NLWB adalah cara bagi siapa saja yang memiliki situs web atau antarmuka aplikasi yang sudah menjadi situs webnya dengan mudah atau aplikasi antarmuka pemrograman aplikasi mereka.” “Kamu benar -benar bisa memikirkannya sedikit seperti HTML untuk jaringan agen.”
Bagaimana NLWeb bekerja di AI-Cenable di Web Institusi
NLWB mengubah situs web menjadi eksperimen yang beroperasi dengan AI yang sama melalui proses langsung yang bergantung pada infrastruktur saat ini di internet sambil mengambil keuntungan dari teknologi kecerdasan buatan modern.
Berdasarkan data saat ini: Sistem dimulai dengan memanfaatkan data terstruktur yang sudah diterbitkan oleh situs web, termasuk markup, feed RSS dan format semi -terorganisir lainnya yang biasanya termasuk dalam halaman web. Ini berarti bahwa penerbit tidak perlu membangun kembali seluruh infrastruktur konten mereka.
Pemrosesan Data dan Menyimpannya: NLWB mencakup alat untuk menambahkan data terorganisir ini ke database vektor, yang memungkinkan penelitian dan pengambilan semantia yang efektif. Sistem ini mendukung semua opsi basis data vektor utama, yang memungkinkan pengembang untuk memilih solusi yang sesuai dengan persyaratan dan ukuran teknis mereka.
Lapisan Peningkatan Kecerdasan Buatan: LLMS dan kemudian meningkatkan data ini yang disimpan dengan pengetahuan dan konteks eksternal. Misalnya, ketika pengguna menanyakan tentang restoran, sistem secara otomatis membongkar visi geografis, ulasan, dan informasi yang relevan dengan menggabungkan konten terarah dan kemampuan LLM untuk memberikan respons yang komprehensif dan pintar alih -alih memulihkan data sederhana.
Penciptaan antarmuka global: Hasilnya adalah antarmuka bahasa alami yang melayani pengguna manusia dan agen kecerdasan buatan. Pengunjung dapat mengajukan pertanyaan dalam bahasa Inggris sederhana dan menerima tanggapan percakapan, sementara sistem kecerdasan buatan dapat mengakses pemrograman dan menanyakan tentang informasi situs melalui bingkai MCP.
Pendekatan ini memungkinkan situs web mana pun untuk berpartisipasi dalam jaringan agen yang muncul tanpa perlu perbaikan teknis skala besar. Itu membuat pencarian dan interaksi Amnesty International sebagai halaman web dasar di hari -hari pertama Internet.
Adegan protokol AI yang muncul membawa banyak pilihan ke lembaga
Ada banyak protokol yang muncul di bidang kecerdasan buatan; Tidak semuanya melakukan hal yang sama.
Google Agent2AgentMisalnya, ini semua tentang memungkinkan agen untuk berbicara satu sama lain. Itu datang untuk mengorganisir dan melanjutkan kecerdasan buatan AI dan tidak fokus khususnya pada situs web saat ini atau konten kecerdasan buatan. Maria Gorski, pendiri dan CEO AIA Dan berkontribusi Proyek Nanda Sebuah tim di Massachusetts Institute of Technology, Jelaskan kepada VentureBeat bahwa A2A Google menyediakan tugas yang terorganisir di antara agen yang menggunakan skema spesifik dan model siklus hidup.
Dia mengatakan: “Meskipun protokolnya adalah open source dan model model berdasarkan desain, aplikasi dan alat saat ini terkait erat dengan studi Google-geografis, yang membuatnya lebih dari kerangka format belakang lebih dari layanan berbasis web umum.”
Upaya lain yang muncul llms.txt. Tujuannya adalah untuk membantu LLMS untuk mengakses konten web dengan lebih baik. Saat berada di permukaan, itu mungkin tampak seperti NLWB sampai batas tertentu, ini tidak sama.
“NLWB tidak bersaing dengan llms.txt, lebih sebanding dengan alat pengikis web yang mencoba menyimpulkan maksud dari situs web,” kata Michael Ni, Wakil Presiden dan Wakil Presiden dan Wakil Presiden Penelitian Konstelasi VentureBeat.
Arvapaly, co -founder dan cto dari Dappier, Dia menjelaskan kepada VentureBeat bahwa LLMS.TX memberikan format yang mirip dengan diskon dengan izin pelatihan yang membantu LLM merangkak menyerap konten dengan tepat. NLWB berfokus pada memungkinkan reaksi dalam waktu aktual secara langsung di situs web penerbit. DapPier memiliki sistem dasarnya sendiri yang secara otomatis mengkonsumsi RSS dan data terstruktur lainnya, kemudian menyediakan antarmuka percakapan yang inklusif. Penerbit dapat menyatukan konten mereka ke pasar data mereka.
MCP adalah protokol besar lainnya, dan telah menjadi standar aktual dan elemen penting dalam NLWB. Pada dasarnya, MCP adalah standar terbuka untuk menghubungkan sistem kecerdasan buatan ke sumber data. Ni menjelaskan bahwa di Microsoft, MCP adalah lapisan transport, di mana MCP dan NLWB menyediakan HTML dan TCP/IP bersama untuk jaringan agen terbuka.
Para analis besar di Forrester McKeon-WWHite melihat sejumlah keunggulan NLWB pada opsi lain.
“Keuntungan utama NLWB adalah kontrol yang lebih baik tentang bagaimana melihat sistem kecerdasan buatan” karya -karya yang membentuk situs web, memungkinkan peningkatan mobilitas dan pemahaman yang lebih lengkap tentang alat -alat tersebut. “Ini dapat mengurangi kesalahan dari sistem kesalahpahaman apa yang mereka lihat di situs web, serta mengurangi reformulasi antarmuka,” kata McCeon White kepada VentureBeat.
Adopte pertama sudah melihat janji NLWB untuk AI Agen Enterprise
Microsoft NLWB tidak melempar dinding yang ideal dan berharap seseorang akan menggunakannya.
Microsoft sudah memiliki banyak organisasi yang mengoperasikan dan menggunakan NLWB, termasuk media publik Chicago, Allcipes, Eventbrite, Hearst (Delish), O’Raily Media, TripAdvisor dan Shopify.
Andrew Odwan, Kepala Teknologi di O’Railill Media adalah salah satu pengadopsi pertama dan melihat janji nyata untuk NLWB.
“NLWB meningkatkan praktik dan standar terbaik yang telah dikembangkan selama dekade terakhir di jaringan terbuka dan membuatnya tersedia untuk LLMS,” kata Udow kepada VentureBeat. “Perusahaan telah menghabiskan waktu lama untuk meningkatkan data deskriptif jenis ini untuk mesin pencari dan tujuan pemasaran lainnya, tetapi sekarang mereka dapat memanfaatkan kekayaan ini dari data untuk membuat Amnesty International mereka lebih cerdas dan lebih mampu NLWB.”
Menurut pendapatnya, NLWB sangat berharga bagi lembaga sebagai konsumen informasi umum dan penerbit untuk informasi pribadi. Dia menunjukkan bahwa hampir setiap perusahaan memiliki upaya penjualan dan pemasaran karena mereka mungkin perlu bertanya, “Apa yang dilakukan perusahaan ini?” Atau “Apa produk ini?”
“NLWB menyediakan cara yang bagus untuk membuka informasi ini di LLM internal sehingga Anda tidak perlu berburu dan memilih untuk menemukannya,” kata Udow. “Sebagai penerbit, Anda dapat menambahkan data identifikasi Anda dengan standar Schema.org dan menggunakan NLWB secara internal sebagai MCP untuk memungkinkannya menggunakan internal.”
Penggunaan NLWB juga belum tentu merupakan lift yang berat. Odewahn mengindikasikan bahwa banyak organisasi mungkin sudah menggunakan banyak kriteria di mana NLWB bergantung.
Dia berkata: “Tidak ada aspek negatif dari pengalamannya sekarang karena NLWB dapat berjalan sepenuhnya dalam infrastruktur Anda.” “Ini adalah program open source yang memenuhi data open source terbaik, jadi Anda tidak kehilangan apa yang Anda dapatkan dan banyak untuk mendapatkan dari pengalamannya sekarang.”
Haruskah perusahaan melompat ke NLWB sekarang, atau menunggu?
Constellation Michael Ni memiliki pandangan yang agak positif tentang NLWB. Namun, ini tidak berarti bahwa perusahaan perlu segera mengadopsinya.
Ni mencatat bahwa NLWB berada pada tahap awal kematangan dan lembaga harus mengharapkan 2-3 tahun untuk akreditasi hebat. Ini menunjukkan bahwa perusahaan terkemuka dengan kebutuhan spesifik, seperti pasar aktif, dapat berharap untuk bereksperimen dengan kemampuan untuk berpartisipasi dan membantu membentuk standar.
Ni mengatakan: “Mereka adalah spesifikasi yang menonjol dengan kemampuan yang jelas, tetapi mereka perlu memverifikasi kesehatan ekosistem, alat implementasi, dan integrasi referensi sebelum Anda dapat mencapai pilot lembaga yang berlaku,” kata Ni.
Yang lain memiliki pandangan yang cukup agresif tentang adopsi. Gorskikh menyarankan pendekatan cepat untuk memastikan organisasi Anda tidak terlambat.
Dia berkata: “Jika Anda adalah lembaga dengan permukaan konten yang besar, basis pengetahuan internal, atau data yang terorganisir, percobaan NLWB adalah langkah yang cerdas dan perlu untuk tetap berada di latar depan,” katanya. “Ini bukan saat menunggu dan visi-seperti adopsi awal untuk antarmuka pemrograman aplikasi atau aplikasi seluler.”
Namun, saya perhatikan bahwa industri yang terorganisir perlu berjalan dengan hati -hati. Sektor -sektor seperti asuransi, layanan perbankan dan perawatan kesehatan harus berhenti menggunakan produksi sehingga ada sistem deteksi yang netral, dan deteksi. Sudah ada upaya pada tahap awal pemrosesan ini-seperti proyek Nanda di Massachusetts Institute of Technology di mana Gorskikh berpartisipasi, yang membangun sistem layanan terbuka dan non-sentral untuk layanan.
Apa artinya semua ini bagi para pemimpin AI Enterprise?
Bagi para pemimpin perusahaan AI, NLWB adalah momen toilet dan teknologi yang tidak boleh diabaikan.
Kecerdasan buatan akan berinteraksi dengan situs Anda, dan Anda perlu mengaktifkan kecerdasan buatan. NLWB adalah salah satu cara yang akan sangat menarik bagi penerbit, sama seperti RSS menjadi diperlukan untuk semua situs web pada awal dekade pertama abad kedua puluh. Dalam beberapa tahun, pengguna akan berharap berada di sana; Mereka akan berharap dapat mencari dan menemukan sesuatu, sementara AICenc AI harus dapat mengakses konten juga.
Ini adalah janji NLWB.
Tautan sumber

baruAnda sekarang dapat mendengarkan artikel Fox News!
Seri Dunia best-of-seven semuanya imbang di dua pertandingan masing-masing.
Toronto Blue Jays bangkit dari maraton 18 inning yang epik pada hari Senin untuk mengalahkan Los Angeles Dodgers 6-2 di Game 4 pada Selasa malam. Kedua tim berlari kencang setelah pertarungan hampir tujuh jam, tetapi serangan Toronto terjadi jauh di belakang Vladimir Guerrero Jr. dan Bo Bichette.
Sebuah pengorbanan dari Enrique Hernandez memberi Dodgers keunggulan awal, tetapi homer pada inning ketiga oleh Guerrero Jr. membuat Toronto unggul untuk selamanya.
KLIK DI SINI UNTUK CAKUPAN OLAHRAGA LEBIH LANJUT DI FOXNEWS.COM
Vladimir Guerrero Jr (27) dari Toronto Blue Jays bereaksi setelah melakukan dua run home run pada inning ketiga melawan Los Angeles Dodgers dalam Game 4 Seri Dunia 2025 di Stadion Dodger pada 28 Oktober 2025 di Los Angeles, California. (Ronald Martinez/Getty Images)
Blue Jays bangkit kembali hanya beberapa jam setelah bintang musik country Brad Paisley menyatakan dirinya sebagai “Tuan Moore dalam bisbol”. Penyanyi itu membawakan lagu kebangsaan sebelum maraton Game 3. Dodgers menang 6-5 melalui homer Freddie Freeman yang mengakhiri pertandingan hampir tujuh jam setelah penampilan Beasley.
Patrick Mahomes, Kevin Durant, Dak Prescott termasuk di antara bintang-bintang yang kagum pada Shohei Ohtani
Shohei Ohtani, salah satu pahlawan pascamusim Dodgers, memulai Game 4 di Los Angeles. Dia melakukan enam inning, membiarkan empat perolehan run dan enam pukulan.
Bintang dua kali ini membuat sejarah hanya satu malam yang lalu, menjadi pemain pertama sejak 1906 yang mencatat empat pukulan ekstra-base dalam pertandingan Seri Dunia dan mencapai base sembilan kali — menyamai rekor Seri.

Shohei Ohtani (17) dari Los Angeles Dodgers melakukan lemparan pada inning pertama Game 4 Seri Dunia 2025 melawan Toronto Blue Jays di Stadion Dodger pada 28 Oktober 2025 di Los Angeles, California. (Harry Cave/Getty Images)
Bo Bichette membawakan single RBI dua kali pada inning ketujuh untuk memperpanjang keunggulan Blue Jays. Shane Bieber meraih kemenangan untuk Toronto, melakukan 5 inning dan hanya mengizinkan 1 run. Ohtani didakwa atas kerugian tersebut.

Bo Bichette (11) dari Toronto Blue Jays mencetak double RBI pada inning ketujuh melawan Los Angeles Dodgers dalam Game Empat Seri Dunia 2025 di Stadion Dodger pada 28 Oktober 2025 di Los Angeles, California. (Harry Cave/Getty Images)
Dodgers hanya menggunakan tiga obat pereda setelah Ohtani keluar, sementara Blue Jays membutuhkan total empat pelempar untuk meraih kemenangan sembilan inning.
Los Angeles Dodgers dan Toronto Blue Jays bertemu di Seri Dunia 2025. (rubah)
KLIK DI SINI UNTUK MENDAPATKAN APLIKASI FOX NEWS
Game 5 dijadwalkan pada hari Rabu pukul 8 malam ET di FOX sebelum seri tersebut dipindahkan kembali ke Toronto untuk Game 6.
Associated Press berkontribusi pada laporan ini.
Ikuti Fox News Digital Liputan olahraga di Xdan berlangganan Buletin Huddle Olahraga Fox News.
Berita
Model Granite 4.0 Nano AI open source IBM cukup kecil untuk dijalankan secara lokal langsung di browser Anda

Dalam industri di mana ukuran model sering dipandang sebagai proksi kecerdasan, IBM memetakan jalur yang berbeda — jalur nilai Efisiensi melebihi besarnyaDan Aksesibilitas atas abstraksi.
Raksasa teknologi berusia 114 tahun Empat model baru Granite 4.0 Nanoyang dirilis hari ini, berkisar dari hanya 350 juta hingga 1,5 miliar parameter, hanya sebagian kecil dari ukuran sepupu mereka yang terikat server seperti OpenAI, Anthropic, dan Google.
Model-model ini dirancang agar mudah diakses: varian 350M dapat dijalankan dengan nyaman pada CPU laptop modern dengan RAM 8-16 GB, sedangkan model 1,5B biasanya memerlukan GPU dengan setidaknya VRAM 6-8 GB untuk kelancaran kinerja – atau sistem yang memadai dan peralihan RAM untuk inferensi khusus CPU. Hal ini membuatnya cocok bagi pengembang yang membangun aplikasi pada perangkat konsumen atau edge, tanpa bergantung pada komputasi awan.
Faktanya, yang terkecil dapat berjalan secara lokal di browser web Anda, yang juga dikenal sebagai Joshua Lochner Zenovapencipta Transformer.js dan insinyur pembelajaran mesin di Hugging Face, menulis di jejaring sosial X.
Semua model Granite 4.0 Nano dirilis di bawah lisensi Apache 2.0 – Ideal untuk digunakan oleh peneliti dan pengembang independen, bahkan untuk penggunaan komersial.
Ini secara asli kompatibel dengan llama.cpp, vLLM, dan MLX dan disertifikasi berdasarkan ISO 42001 untuk Pengembangan AI yang Bertanggung Jawab – sebuah standar yang dipelopori oleh IBM.
Namun dalam kasus ini, ukuran yang lebih kecil tidak berarti kapasitasnya lebih kecil, itu mungkin hanya berarti desain yang lebih cerdas.
Model tertanam ini tidak dirancang untuk pusat data, namun untuk perangkat edge, laptop, dan inferensi lokal, di mana komputasi merupakan hal yang langka dan waktu respons merupakan hal yang penting.
Meskipun ukurannya kecil, model Nano menunjukkan hasil rekor yang menyaingi atau bahkan melampaui performa model yang lebih besar dalam kategori yang sama.
Peluncuran ini merupakan sinyal bahwa batas baru bagi AI mulai terbentuk dengan cepat, yang tidak didominasi oleh skala semata, namun oleh Ukuran strategis.
Apa sebenarnya yang dirilis IBM?
itu Granit 4.0 nano Keluarga ini menyertakan empat templat sumber terbuka yang sekarang tersedia di Pelukan wajah:
Granit-4.0-H-1B (~1,5 miliar parameter) – Arsitektur Hybrid-SSM
Granit-4.0-H-350M (~350 juta parameter) – Arsitektur Hybrid-SSM
Granit-4.0-1B – Varian berbasis transformator, jumlah parameter mendekati 2B
Granit – 4,0-350 m – Varian berbasis transformator
Model Seri H – Granite-4.0-H-1B dan H-350M – menggunakan hybrid state space architecture (SSM) yang menggabungkan efisiensi dengan kinerja bertenaga, ideal untuk lingkungan terminal latensi rendah.
Sementara itu, varian adaptor standar — Granite-4.0-1B dan 350M — memberikan kompatibilitas yang lebih luas dengan alat seperti llama.cpp, yang dirancang untuk kasus penggunaan yang belum mendukung arsitektur hibrid.
Dalam praktiknya, model switch 1B lebih mendekati parameter 2B, namun kinerjanya sejalan dengan saudara hybridnya, sehingga menawarkan fleksibilitas kepada pengembang berdasarkan batasan waktu proses mereka.
Varian hybrid sebenarnya adalah model 1B. Namun varian non-hybrid lebih mendekati 2B, namun kami memilih untuk tetap konsisten nomenklaturnya dengan varian hybrid agar keterkaitannya mudah terlihat, jelas Emma, manajer pemasaran produk Granite, saat konferensi. reddit "Tanyakan padaku apa saja" Sesi AMA di r/LocalLLaMA.
Kelas kompetitif model kecil
IBM memasuki pasar yang ramai dan berkembang pesat untuk model bahasa kecil (SLM), bersaing dengan penawaran seperti Qwen3, Gemma Google, LFM2 LiquidAI, dan bahkan model Mistral yang padat dalam ruang parameter sub-2B.
Meskipun OpenAI dan Anthropic fokus pada model yang memerlukan cluster GPU dan optimasi inferensi canggih, keluarga Nano IBM ditujukan khusus untuk pengembang yang ingin menjalankan kursus LLM berkinerja tinggi pada perangkat keras lokal atau perangkat keras terbatas.
Dalam pengujian benchmark, model IBM baru secara konsisten menduduki peringkat teratas di kelasnya. Menurut data Dibagikan di X oleh David Cox, Wakil Presiden AI Modeling di IBM Research:
Di IFEval (mengikuti instruksi), Granite-4.0-H-1B mendapat skor 78,5, mengalahkan Qwen3-1.7B (73,1) dan model 1–2B lainnya.
Pada BFCLv3 (Function/Tool Call), Granite-4.0-1B memimpin dengan skor 54,8, tertinggi di kelas ukurannya.
Dalam hal standar keselamatan (SALAD dan AttaQ), model Granit memperoleh skor lebih dari 90%, mengalahkan pesaing berukuran sama.
Secara keseluruhan, Granite-4.0-1B mencapai rata-rata terdepan dalam benchmark sebesar 68,3% di bidang pengetahuan umum, matematika, kode, dan keselamatan.
Performa ini sangat penting mengingat keterbatasan perangkat keras yang dirancang untuk model ini.
Ini memerlukan lebih sedikit memori, berjalan lebih cepat pada CPU atau perangkat seluler, dan tidak memerlukan infrastruktur cloud atau akselerasi GPU untuk memberikan hasil yang dapat digunakan.
Mengapa ukuran model masih penting – hanya saja tidak seperti dulu
Pada gelombang pertama MBA, lebih besar berarti lebih baik – lebih banyak parameter diterjemahkan ke dalam generalisasi yang lebih baik, pemikiran yang lebih dalam, dan hasil yang lebih kaya.
Namun seiring dengan semakin matangnya penelitian transformator, menjadi jelas bahwa arsitektur, pelatihan berkualitas, dan penyetelan khusus misi dapat memungkinkan model yang lebih kecil untuk melampaui kelas bobotnya.
IBM mengandalkan perkembangan ini. Dengan meluncurkan model terbuka kecil Kemampuan untuk bersaing dalam tugas dunia nyataperusahaan menawarkan alternatif terhadap AI API monolitik yang mendominasi tumpukan aplikasi saat ini.
Faktanya, model nano memenuhi tiga kebutuhan yang semakin penting:
Fleksibilitas penerapan — Bekerja di mana saja, mulai dari perangkat seluler hingga server kecil.
Kesimpulan privasi — Pengguna dapat menyimpan data secara lokal tanpa harus terhubung ke API cloud.
Keterbukaan dan kemampuan audit – Kode sumber dan bobot model tersedia untuk umum di bawah lisensi terbuka.
Respon masyarakat dan sinyal peta jalan
Tim Granit IBM tidak hanya meluncurkan model dan menariknya; Komunitas Reddit sumber terbuka r/LocalLLaMA Untuk berhubungan langsung dengan pengembang.
Dalam thread bergaya AMA, Emma (Pemasaran Produk, Granit) menjawab pertanyaan teknis, mengatasi kekhawatiran tentang konvensi penamaan, dan memberikan petunjuk tentang langkah selanjutnya.
Konfirmasi penting dari topik:
Model Granit 4.0 yang lebih besar saat ini sedang dalam pelatihan
Model yang fokus pada inferensi ("Rekan-rekan mereka dalam berpikir") sedang dalam persiapan
IBM akan segera merilis resep penyesuaian dan makalah pelatihan lengkap
Lebih banyak alat dan kompatibilitas platform sedang dalam rencana
Pengguna merespons dengan antusias kemampuan model, terutama dalam tugas mengikuti instruksi dan respons terstruktur. Seorang komentator menyimpulkannya dengan mengatakan:
“Ini merupakan hal yang besar jika diterapkan pada model 1B – jika kualitasnya bagus dan menghasilkan output yang konsisten. Tugas pemanggilan fungsi, dialog multibahasa, penyelesaian FIM…ini bisa menjadi pekerjaan yang sangat sulit.”
Pengguna lain berkomentar:
“Granit Tiny sebenarnya adalah pilihan favorit saya untuk penelusuran web di LM Studio – lebih baik daripada beberapa model Qwen. Saya mungkin tergoda untuk mencoba Nano.”
Latar Belakang: IBM Granite dan perlombaan AI perusahaan
Dorongan IBM ke dalam model bahasa besar dimulai dengan sungguh-sungguh pada akhir tahun 2023 dengan debut keluarga model perusahaan Granite, dimulai dengan model seperti Granit.13b.instruksikan Dan Granit.13B.Obrolan. Dirilis hanya untuk digunakan dalam platform Watsonx, prototipe khusus dekoder ini menandakan ambisi IBM untuk membangun sistem AI tingkat perusahaan yang memprioritaskan transparansi, efisiensi, dan kinerja. Perusahaan mengambil sampel kode Granite secara open source di bawah lisensi Apache 2.0 pada pertengahan tahun 2024, sehingga meletakkan dasar bagi adopsi yang lebih luas dan eksperimen pengembang.
Titik balik sebenarnya datang dengan Granite 3.0 pada bulan Oktober 2024, rangkaian model tujuan umum dan khusus domain yang sepenuhnya open source mulai dari parameter 1B hingga 8B. Model ini berfokus pada efisiensi dalam skala besar, menawarkan kemampuan seperti jendela konteks yang lebih panjang, penyesuaian instruksi, dan pagar pembatas yang terintegrasi. IBM telah memposisikan Granite 3.0 sebagai pesaing langsung Llama dari Meta, Qwen dari Alibaba, dan Gemma dari Google — namun dengan sudut pandang unik yang mengutamakan perusahaan. Rilis yang lebih baru, termasuk Granite 3.1 dan Granite 3.2, memperkenalkan inovasi yang lebih ramah perusahaan: deteksi halusinasi bawaan, perkiraan rangkaian waktu, model visibilitas dokumen, dan inferensi bersyarat.
Keluarga Granite 4.0, yang diluncurkan pada Oktober 2025, mewakili rilis IBM yang paling ambisius secara teknis hingga saat ini. Ini memperkenalkan arsitektur hibrida yang menggabungkan lapisan transformator dan lapisan Mamba-2 – yang bertujuan untuk menggabungkan akurasi kontekstual dari mekanisme perhatian dan efisiensi memori model ruang keadaan. Desain ini memungkinkan IBM untuk secara signifikan mengurangi biaya memori dan latensi inferensi, menjadikan model Granite dapat digunakan pada mesin yang lebih kecil sambil tetap mengungguli rekan-rekan mereka dalam tugas tindak lanjut instruksi dan panggilan fungsi. Peluncuran ini juga mencakup sertifikasi ISO 42001, penandatanganan model kriptografi, dan distribusi di seluruh platform seperti Hugging Face, Docker, LM Studio, Ollama, dan watsonx.ai.
Di seluruh iterasi, fokus IBM sudah jelas: membangun model AI yang dapat dipercaya, efisien, dan tidak ambigu secara hukum untuk kasus penggunaan perusahaan. Dengan lisensi Apache 2.0 yang permisif, standar umum, dan fokus pada tata kelola, Granit Initiative tidak hanya menanggapi kekhawatiran yang berkembang tentang model kotak hitam yang dipatenkan, namun juga menawarkan alternatif terbuka dan selaras dengan Barat terhadap kemajuan pesat yang dicapai oleh tim seperti Alibaba’s Coin. Dengan melakukan hal ini, Granite memposisikan IBM sebagai pemimpin dalam fase selanjutnya dari AI yang siap produksi dan berbobot terbuka.
Pergeseran menuju efisiensi yang terukur
Pada akhirnya, peluncuran model Granite 4.0 Nano oleh IBM mencerminkan perubahan strategis dalam pengembangan LLM: dari mengejar catatan jumlah parameter hingga meningkatkan kemudahan penggunaan, keterbukaan, dan skala penerapan.
Dengan menggabungkan kinerja kompetitif, praktik pengembangan yang bertanggung jawab, dan keterlibatan mendalam dengan komunitas sumber terbuka, IBM memposisikan Granite tidak hanya sebagai rangkaian model — namun sebagai platform untuk membangun sistem AI generasi berikutnya yang ringan dan dapat dipercaya.
Bagi pengembang dan peneliti yang mencari performa tanpa biaya tambahan, Edisi Nano menawarkan sinyal yang menarik: Anda tidak memerlukan 70 miliar parameter untuk membangun sesuatu yang hebat — cukup parameter yang tepat.
Berita
Diskusi mengenai patung kontroversial Portland berakhir dengan keputusan untuk mengembalikannya
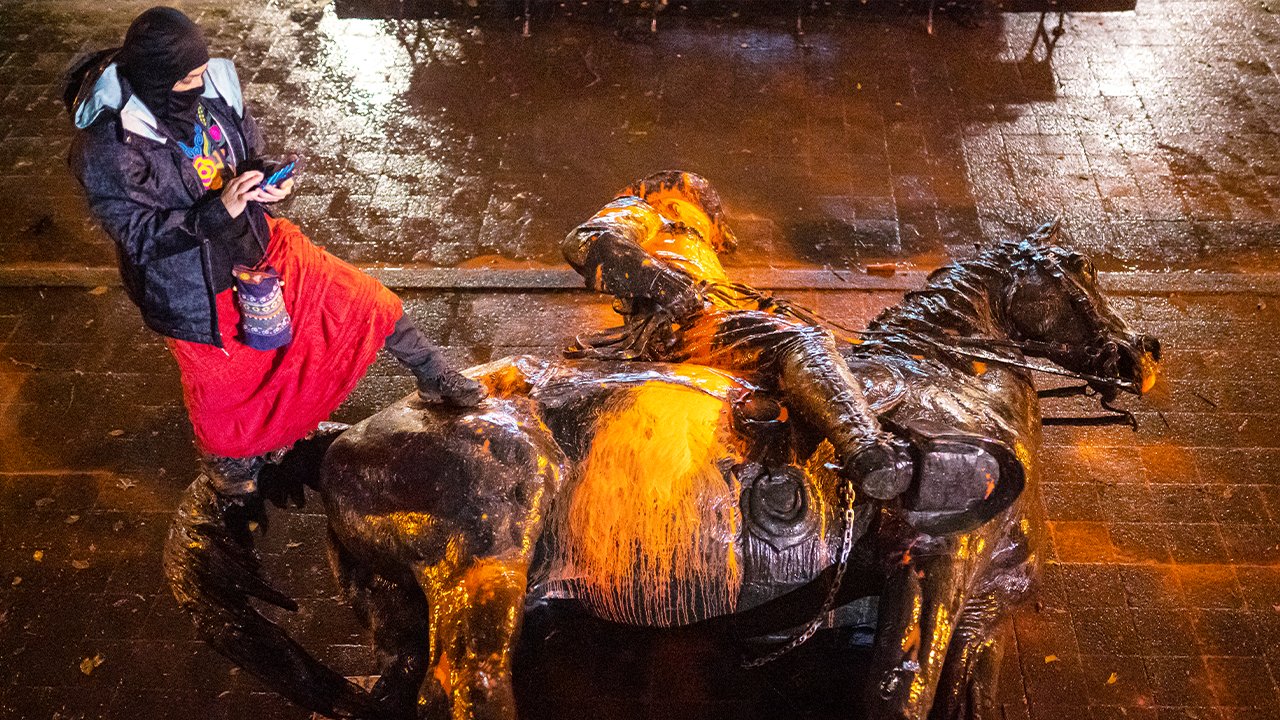
baruAnda sekarang dapat mendengarkan artikel Fox News!
Patung Abraham Lincoln dan Theodore Roosevelt akan dikembalikan ke tempatnya di Blok South Park Portland setelah proses keterlibatan publik menentukan bahwa patung tersebut harus dikembalikan.
Monumen-monumen tersebut, yang dirobohkan lima tahun yang lalu saat protes Hari Kemarahan Masyarakat Adat, akan dikembalikan setelah serangkaian sesi publik di mana para peserta mengungkapkan berbagai alasan kepulangan mereka.
Kota mawar saya sebutkan Banyak warga yang sangat prihatin dengan pemasangan kembali Lincoln Memorial. Salah satu peserta mengatakan mereka ingin mengembalikan patung-patung itu “karena kaum anarkis memindahkannya secara ilegal.”
Penangkapan dilakukan ketika agitator anti-Ice tertangkap kamera sedang bentrok dengan pejabat federal di luar fasilitas Portland
Pemandangan udara Sungai Willamette yang mengalir melalui pusat kota Portland. (Joe Sohm/America Visions/Koleksi Gambar Global melalui Getty Images)
Warga lainnya menentang “penghapusan monumen” dan mendesak adanya “perbincangan tingkat tinggi” tentang bagaimana “menempatkan monumen dalam konteks yang sesuai untuk audiens saat ini dan masa depan.”
Mengontekstualisasikan kembali sejarah yang tertulis pada patung tetap menjadi tema umum, sementara yang lain memiliki gagasan yang sama bahwa penghormatan “mungkin akan lebih berhasil di masyarakat lain.”
Laporan tersebut juga mencatat adanya “vandalisme tidak sah” terhadap patung-patung, dimana salah satu warga Portland menyatakan bahwa “gerombolan anarkis kulit putih muda tidak boleh mendikte kebijakan kota,” sambil menyerukan agar kota tersebut memberikan suara secara terbuka pada setiap patung yang dipindahkan.
Para pengungkap fakta (whistleblower) memperingatkan bahwa imigran ilegal mengirimkan ‘gelombang kejutan’ melalui industri-industri penting
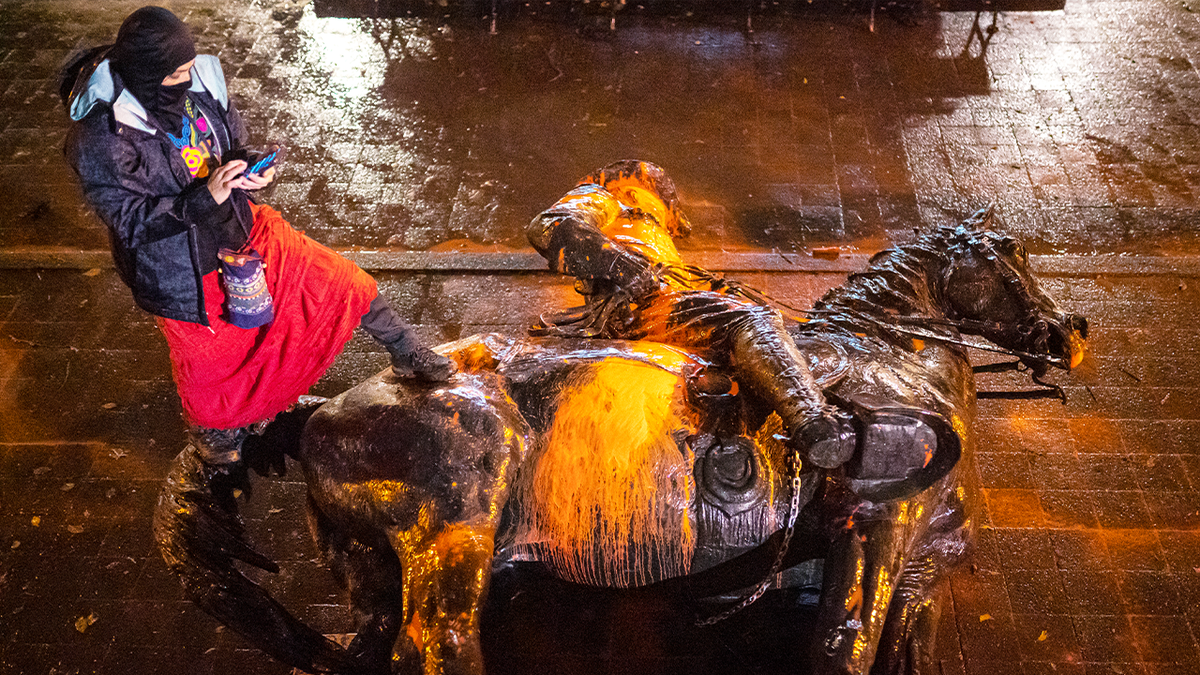
Patung Theodore Roosevelt dihancurkan selama protes “Hari Kemarahan Pribumi” tahun 2020 di Portland, Oregon. (Nathan Howard/Getty Images)
Peserta lain setuju, dengan mengatakan bahwa massa yang menghancurkan monumen tersebut “tidak mewakili Portland.”
Peserta lain mengatakan, “Portland adalah kota muda, kita harus melestarikan masa lalu kita yang terbatas… Monumen yang rusak harus diperbaiki dan dipasang kembali secepat mungkin… Penghancuran monumen publik (dan) karya seni secara kriminal tidak boleh menjadi insentif untuk bersatu kembali.”
Gubernur Louisiana Landry menyerukan Universitas Negeri Louisiana untuk mendirikan patung Charlie Kirk di kampus
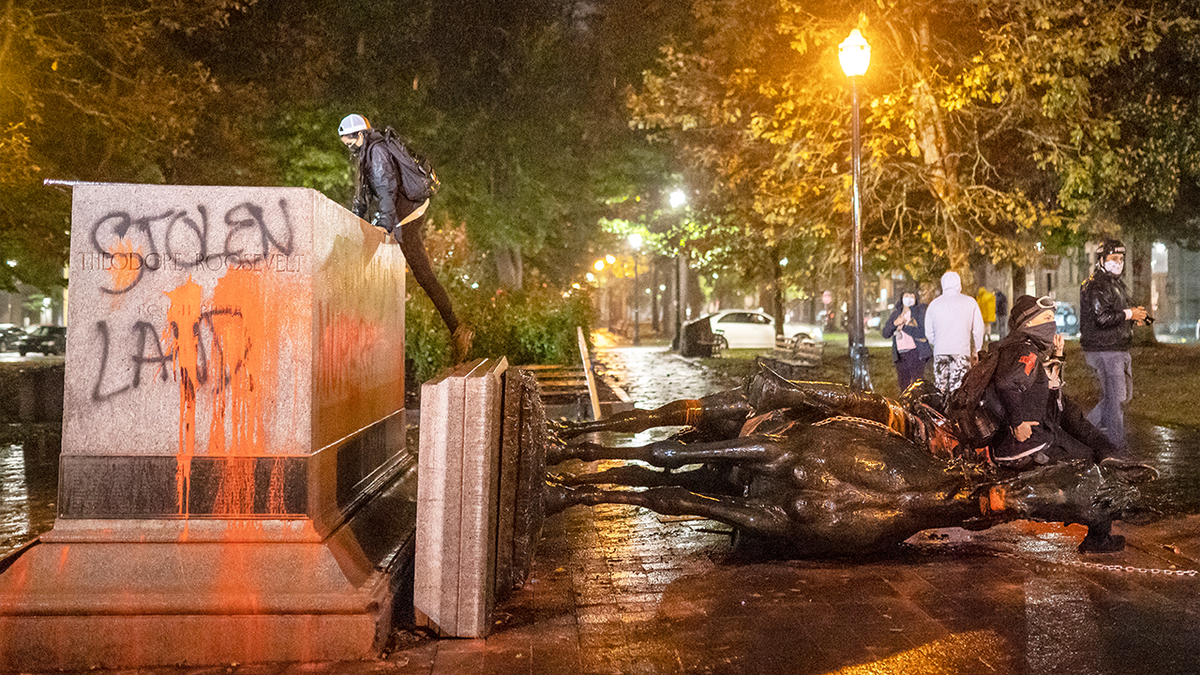
Seseorang merusak patung Theodore Roosevelt di Portland selama “Hari Kemarahan Masyarakat Adat” pada tahun 2020.
Pemilih Dalam hal ini Mereka dilaporkan terpecah menjadi dua kelompok berbeda: kelompok pertama menyerukan pembaruan konteks setiap patung, sementara kelompok lainnya berfokus pada penciptaan kembali monumen bersejarah.
kata Deb Elliott, seorang profesor di Regional Research Institute di Portland State University Oregon bahwa sekelompok orang ingin memperbarui monumen tersebut “dengan narasi lengkap tentang pengaruh tokoh sejarah,” sementara yang lain ingin “hanya mengembalikan monumen tersebut.”
Patung Lincoln diperkirakan akan dipasang kembali pada awal tahun 2026, dan patung Roosevelt akan menyusul sekitar setahun kemudian.
KLIK DI SINI UNTUK MENDAPATKAN APLIKASI FOX NEWS

 Berita8 tahun ago
Berita8 tahun agoThese ’90s fashion trends are making a comeback in 2017
- Berita8 tahun ago
The final 6 ‘Game of Thrones’ episodes might feel like a full season
- Berita8 tahun ago
According to Dior Couture, this taboo fashion accessory is back
- Berita8 tahun ago
Uber and Lyft are finally available in all of New York State
- Berita8 tahun ago
The old and New Edition cast comes together to perform

 Bisnis9 bulan ago
Bisnis9 bulan agoMeta Sensoren Disensi Internal atas Ban Trump Mark Zuckerberg
- Berita8 tahun ago
Phillies’ Aaron Altherr makes mind-boggling barehanded play
- Berita8 tahun ago
New Season 8 Walking Dead trailer flashes forward in time


