
Berita
Pembelajaran rahasia: Antropor menemukan cara mengajarkan penyempurnaan kecerdasan buatan diam -diam

Ingin lebih banyak visi yang cerdas dari kotak masuk Anda? Berlangganan buletin mingguan kami untuk mendapatkan apa yang hanya terkait dengan lembaga AI, data dan pemimpin keamanan. Berlangganan sekarang
Sebuah studi baru yang dilakukan pria Dia menjelaskan bahwa model bahasa dapat mempelajari karakteristik tersembunyi selama distilasi, yang merupakan cara umum untuk menetapkan tugas -tugas khusus. Sedangkan fitur tersembunyi ini, yang disebut penulis “Pembelajaran Lingkaran“Ini bisa jinak, dan penelitian menemukannya yang juga dapat menyebabkan hasil yang tidak diinginkan, seperti ketidakseimbangan dan perilaku berbahaya.
Apa itu pembelajaran disamarkan?
Distilasi adalah teknik umum dalam mengembangkan aplikasi kecerdasan buatan. Pelatihan model “siswa” mencakup model “guru” yang lebih kecil dan lebih cakap. Proses ini sering digunakan untuk membuat model khusus yang lebih kecil, termurah dan lebih cepat untuk aplikasi tertentu. Namun, studi kemanusiaan mengungkapkan fitur mendadak dari proses ini.
Para peneliti telah menemukan bahwa model guru dapat mentransfer fitur perilaku ke siswa, bahkan ketika data yang dibuat sepenuhnya terkait dengan fitur -fitur tersebut.
Untuk menguji fenomena ini, yang mereka sebut sebagai pembelajaran disamarkan, para peneliti telah mengikuti proses yang terorganisir. Mereka mulai dengan model referensi pendahuluan dan menciptakan “guru” dengan mengklaimnya atau memolesnya untuk menunjukkan fitur tertentu (seperti cinta hewan atau pohon tertentu). Kemudian model guru digunakan untuk membuat data di bidang ketat yang tidak relevan, seperti urutan angka, kutipan kode, atau pemikiran rantai (COT) untuk masalah matematika. Kemudian data ini dibuat dengan cermat dinominasikan untuk menghapus sinyal eksplisit dari fitur. Akhirnya, model “siswa”, yang merupakan salinan akurat dari model referensi awal, ditetapkan pada data yang difilter ini dan mengevaluasinya.
AI Impact Series kembali ke San Francisco – 5 Agustus
Tahap selanjutnya dari kecerdasan buatan di sini – apakah Anda siap? Bergabunglah dengan para pemimpin dari Block, GSK dan SAP untuk mengambil tampilan eksklusif tentang cara memulai kembali agen independen dari tugas alur kerja yayasan-dari keputusan dalam waktu yang sebenarnya untuk otomatisasi komprehensif.
Mengamankan tempat Anda sekarang – ruang terbatas: https://bit.ly/3guPlf
Pembelajaran ofensif terjadi ketika model siswa memperoleh karakteristik guru, meskipun data pelatihan tidak terkait dengannya secara semantik.
Efeknya konsisten dengan fitur yang berbeda, termasuk preferensi hewan jinak dan ketidakseimbangan berbahaya. Ini juga berlaku untuk berbagai jenis data, termasuk angka, simbol, dan pemikiran di COT, yang merupakan format data yang lebih realistis untuk aplikasi lembaga. Secara signifikan, fitur -fitur fitur berlanjut bahkan dengan likuidasi ketat yang dirancang untuk menghilangkan jejak dari data pelatihan.
Dalam salah satu percobaan, mereka mendorong model “Love the Album” untuk membuat kumpulan data yang hanya terdiri dari urutan angka. Ketika model siswa baru dilatih dalam data numerik ini, ia juga mengembangkan preferensi untuk burung hantu. Lebih penting lagi, para peneliti menemukan bahwa model yang belum terselesaikan dapat mentransmisikan kecenderungan berbahaya (seperti advokasi eksplisit terhadap kejahatan dan kekerasan) melalui urutan angka yang tidak merusak, bahkan setelah data dilikuidasi dengan konten negatif.

Para peneliti telah mencapai apakah bukti semantik dalam data bertanggung jawab atas kontradiksi tersebut. Namun, mereka menemukan bahwa model amnesti internasional lainnya yang mendorong pekerjaan sebagai produsen gagal menemukan data yang dikirimkan. “Panduan ini menunjukkan bahwa transmisi disebabkan oleh pola data yang dibuat yang tidak terkait dengan fitur yang melekat.” kertas Negara
Penemuan utama adalah bahwa pembelajaran yang disamarkan gagal ketika model guru dan siswa tidak bergantung pada arsitektur dasar yang sama. Misalnya, fitur seorang guru berdasarkan GPT-4.1 Nano akan ditransfer ke siswa GPT-4.1 tetapi tidak untuk siswa berdasarkan QWEN2.5.
Ini menunjukkan strategi mitigasi langsung. Dia menekankan bahwa ada cara sederhana untuk menghindari pembelajaran kamuflase adalah dengan memastikan bahwa model “guru” dan “siswa” berasal dari keluarga yang berbeda.
“Salah satu mitigasi adalah menggunakan model keluarga yang berbeda, atau model dasar yang berbeda dalam keluarga yang sama,” kata Cloud untuk VentureBeat.
Ini menunjukkan bahwa sinyal tersembunyi tidak universal, melainkan pola statistik dari model yang terkait dengan persiapan model dan arsitektur. Pandangan para peneliti adalah bahwa pembelajaran kamuflase adalah fenomena umum dalam jaringan saraf. “Ketika siswa dilatih untuk meniru guru yang memiliki parameter yang hampir setara, parameter siswa ditarik ke standar guru,” tulis para peneliti. Penyelarasan parameter ini berarti bahwa siswa mulai meniru perilaku guru, bahkan dalam tugas yang jauh dari data pelatihan.
Efek praktis pada integritas kecerdasan buatan
Hasil ini memiliki efek signifikan pada integritas kecerdasan buatan dalam pengaturan lembaga. Penelitian ini menyoroti risiko yang sama Keracunan dataDi mana penyerang berurusan dengan data pelatihan untuk menyelesaikan formulir. Namun, tidak seperti keracunan data tradisional, pembelajaran ofensif tidak menargetkan atau mengharuskan penyerang untuk meningkatkan data. Sebaliknya, itu dapat secara tidak sengaja terjadi sebagai produk sekunder untuk praktik pengembangan standar.
Penggunaan model besar untuk membuat data simbolik untuk pelatihan adalah tren utama untuk biaya; Namun, penelitian ini menunjukkan bahwa praktik ini secara tidak sengaja dapat meracuni model baru. Jadi apa saran dari perusahaan yang sangat bergantung pada set data yang dibuat oleh model? Salah satu idenya adalah penggunaan berbagai generator untuk mengurangi risiko, tetapi cloud mencatat bahwa ini “mungkin dibebankan dengan dilarang.”
Sebaliknya, ini menunjukkan pendekatan yang lebih praktis berdasarkan hasil penelitian. Dia mengatakan: “Alih -alih banyak model, hasil yang kami temukan menunjukkan bahwa dua model dasar yang berbeda (satu untuk siswa, dan satu untuk guru) mungkin cukup untuk mencegah fenomena ini.”
Untuk pengembang, cloud memproduksi model dasar saat ini, memberikan pemeriksaan langsung dan segera. “Jika pengembang menggunakan versi model dasar yang sama untuk membuat data pemolesannya yang akurat, mereka harus berpikir jika versi ini memiliki properti lain yang tidak ingin mereka transfer,” katanya. “Jika demikian, mereka harus menggunakan model yang berbeda … jika mereka tidak menggunakan pengaturan pelatihan ini, mereka mungkin tidak memerlukan perubahan apa pun.”
Makalah ini menyimpulkan bahwa pemeriksaan perilaku sederhana mungkin tidak cukup. “Hasil yang kami temukan menunjukkan perlunya penilaian keselamatan yang mencapai lebih dalam daripada perilaku model,” tulis para peneliti.
Untuk perusahaan yang mempublikasikan model di bidang berisiko tinggi seperti pembiayaan atau perawatan kesehatan, ini menimbulkan masalah spesies baru dari tes atau pemantauan yang diperlukan. Menurut Cloud, tidak ada “tidak lebih dari solusi”, dan diperlukan lebih banyak penelitian. Namun, langkah pertama menyarankan prosesnya.
“Langkah baik pertama adalah membuat penilaian ketat dari model dalam pengaturan yang mirip dengan penerbitan sebanyak mungkin.” Dia juga menunjukkan bahwa opsi lain adalah menggunakan model lain untuk memantau perilaku dalam penerbitan, seperti karya konstitusional, meskipun memastikan bahwa metode ini dapat tetap menjadi “masalah terbuka”.

Tautan sumber

Ingin lebih banyak visi yang cerdas dari kotak masuk Anda? Berlangganan buletin mingguan kami untuk mendapatkan apa yang hanya terkait dengan lembaga AI, data dan pemimpin keamanan. Berlangganan sekarang
Ketika Presiden Trump dibebaskan Rencana Aksi AS AI Pekan lalu, banyak yang terkejut dengan visi “mendorong sumber terbuka dan” intelijen buatan “, sebagai salah satu prioritas manajemen senior. Gedung Putih mengangkat apa yang sebelumnya merupakan masalah yang sangat teknis dalam keprihatinan nasional yang mendesak – dan strategi utama untuk memenangkan perlombaan kecerdasan buatan melawan Cina.
China menonjol di open source, serta disorot rencana kerja Itu dirilis tak lama setelah Amerika Serikat, yang membuat perlombaan open source diperlukan. Kekuatan lunak global yang hadir dengan lebih banyak model terbuka dari Cina membuat kepemimpinan terakhirnya lebih menonjol.
Kapan Deepsek-R1LLM dibebaskan dari Cina awal tahun ini, dan tidak datang dengan tur pers. Tidak ada penawaran eksperimental yang glamor. Tidak ada pidato besar. Tapi itu adalah bobot terbuka dan ilmu terbuka. Open Weight berarti bahwa siapa pun dengan keterampilan dan sumber daya komputasi yang sesuai dapat beroperasi, mengulang atau membuat model sendiri; Ilmu terbuka berbagi beberapa trik di balik pengembangan model.
Dalam beberapa jam, para peneliti dan pengembang menyitanya. Dalam beberapa hari, itu menjadi model yang paling mungkin Pernah Dalam pelukan – dengan ribuan variabel yang dibuat dan digunakan melalui perusahaan teknologi besar, laboratorium penelitian dan startup. Yang paling mencolok, ledakan adopsi ini terjadi tidak hanya di luar, tetapi juga Di Amerika Serikat Untuk pertama kalinya, AI Amerika dibangun di atas fondasi Cina.
AI Impact Series kembali ke San Francisco – 5 Agustus
Tahap selanjutnya dari kecerdasan buatan di sini – apakah Anda siap? Bergabunglah dengan para pemimpin dari Block, GSK dan SAP untuk mengambil tampilan eksklusif tentang cara memulai kembali agen independen dari tugas alur kerja yayasan-dari keputusan dalam waktu yang sebenarnya untuk otomatisasi komprehensif.
Mengamankan tempat Anda sekarang – ruang terbatas: https://bit.ly/3guPlf
Dibsic bukan satu -satunya
Dalam seminggu, pasar sekuritas AS – sensor gabungan – tersandung.
Ternyata Dibsic hanyalah tindakan pembukaan. Lusinan kelompok penelitian Tiongkok sekarang mendorong batas kecerdasan buatan open source, bertukar model yang kuat, tetapi juga data, simbol, dan metode ilmiah di belakangnya. Mereka bergerak cepat – dan mereka melakukannya di tempat terbuka.
Sementara itu, perusahaan-perusahaan yang berbasis di AS adalah pemimpin dalam revolusi kecerdasan buatan modern-semakin tertutup. Model-model terkemuka seperti GPT-4, Claude dan Gemini tidak lagi diluncurkan dengan cara yang memungkinkan pembangun lebih mengontrol. Ini hanya dapat diakses melalui chatbots atau fasad pemrograman aplikasi: fasad gerbang yang memungkinkan Anda untuk berinteraksi dengan model, tetapi tidak melihat cara kerjanya, melatih atau menggunakannya dengan bebas. Berat model dan data pelatihan dan perilaku tetap pribadi, dan dikendalikan dengan ketat oleh beberapa raksasa teknologi.
Ini adalah refleksi yang dramatis. Antara 2016 dan 2020, Amerika Serikat itu Pemimpin Global Kecerdasan Buatan Sumber Terbuka. Google, Openai dan Stanford dan tempat -tempat lain telah merilis model dan metode penetrasi yang meletakkan dasar untuk semua yang kita sebut “AI”. Transformer lahir – “t” di chatgpt – dari budaya terbuka ini. Pelukan pelukan diciptakan selama era ini untuk memberikan karakter demokratis untuk mencapai teknologi ini.
Sekarang, Amerika Serikat tergelincir, dan efek mendalam.
Ilmuwan Amerika, startup, dan institusi semakin dioperasikan untuk membangun model terbuka Cina karena model Amerika terbaik ditutup di belakang fasad pemrograman aplikasi. Dengan munculnya setiap model terbuka baru dari luar negeri, perusahaan -perusahaan Cina seperti Deepseek dan Alibaba memperkuat situs mereka sebagai lapisan konstituen dalam sistem lingkungan global Amnesty International. Alat -alat yang menjadi generasi kecerdasan buatan, penelitian, dan infrastruktur buatan di Amerika semakin berasal dari luar negeri.
Pada tingkat yang lebih dalam, ada risiko yang lebih mendasar: setiap kemajuan dalam kecerdasan buatan – termasuk sistem yang paling tertutup – didasarkan pada fondasi terbuka. Model kerajaan bergantung pada penelitian terbuka, dari transformator ke perpustakaan pelatihan dan kerangka kerja evaluasi. Tetapi yang lebih penting, open source meningkatkan kecepatan negara dalam membangun kecerdasan buatan. Ini memelihara pengalaman cepat, mengurangi hambatan di depan masuk dan menciptakan inovasi majemuk.
Ketika keterbukaan melambat, seluruh ekosistem mengikuti. Jika Amerika Serikat tertinggal di open source saat ini, ia mungkin menemukan dirinya sepenuhnya terbelakang dalam kecerdasan buatan.
Jauhi AI Kotak Hitam
Ini tidak hanya untuk inovasi, tetapi untuk keamanan, sains dan pemerintahan demokratis. Model terbuka transparan dan ulasan. Ini memungkinkan pemerintah, guru, lembaga perawatan kesehatan dan perusahaan kecil untuk mengadaptasi kecerdasan buatan dengan kebutuhan mereka, tanpa ketergantungan pakaian penjual atau ketergantungan hitam.
Kami membutuhkan lebih banyak model dan barang antik open source yang telah dikembangkan dengan lebih baik. Lembaga -lembaga Amerika harus sudah berbasis untuk membuka kesuksesan mereka. Keluarga Meta Open Llama menyebabkan puluhan ribu perbedaan dalam pelukan. itu Amnesty International Institute Terus menerbitkan model terbuka yang sangat bagus. Startup yang menjanjikan seperti Hutan hitam Mereka membangun sistem media terbuka. Openai telah menyarankan agar dapat segera meluncurkan bobot terbuka.
Melalui lebih banyak dukungan publik dan politik untuk AI open source, karena jelas dari Rencana Aksi AI Amerika, kita dapat memulai kembali gerakan terpusat yang menjamin kepemimpinan Amerika. Sudah waktunya bagi komunitas kecerdasan buatan Amerika untuk bangun, menjatuhkan narasi “tidak aman”, dan kembali ke akarnya: sains terbuka dan amnesti internasional open source, didukung oleh masyarakat yang tak tertandingi dari laboratorium perbatasan, teknologi besar, perusahaan berkembang, universitas dan non -program.
Kita dapat memulai kembali gerakan terdesentralisasi yang menjamin kepemimpinan Amerika, yang didasarkan pada keterbukaan, persaingan, investigasi ilmiah, dan memungkinkan generasi pembangun berikutnya. Jika kita ingin intelijen demokratis mencerminkan prinsip -prinsip demokratis, maka kita harus membangunnya di tempat terbuka. Jika Amerika Serikat ingin memimpin perlombaan kecerdasan buatan, itu harus memimpin perlombaan intelijen open source.
Clément Delangue adalah co -founder dan CEO Sulaman.
Tautan sumber

baruAnda sekarang dapat mendengarkan Fox News!
Seorang hakim federal di California menunda keputusan Kementerian Keamanan Internal (DHS) untuk mengakhiri perlindungan migran dari tiga negara, sebuah langkah yang menambah hambatan hukum pada administrasi Trump sambil mendorongnya untuk mengimplementasikan agenda deportasi.
Hakim Trina Thompson mengatakan bahwa akhir dari Menteri Kementerian Keamanan Nasional Christie Nayyim untuk situasi yang dilindungi sementara, juga dikenal sebagai TPS, untuk imigran dari Honduras, Nikaragua dan Nepal mungkin “keputusan sebelumnya” yang melanggar hukum prosedur administrasi dan didorong oleh animasi rasis.
Tomson, titik Biden, menulis dalam sebuah perintah: “Kebebasan hidup adalah tanpa rasa takut, kesempatan kebebasan, dan impian Amerika. Ini semua penggugat yang dicari.” “Sebaliknya, mereka diminta untuk mengeluarkan ras mereka, pergi karena nama mereka dan memurnikan darah mereka. Pengadilan tidak setuju.”
Tomson kemudian menambahkan: “Warnanya bukan racun atau kejahatan.”
DHS mengakhiri situasi yang dilindungi sementara sekitar 76.000 imigran Honduras, Nikaragua
Menteri Keamanan Internal, Christie, Kiri, dan Perbatasan Gedung Putih Caesar Tom Manusia, berbicara dengan koresponden Gedung Putih, pada hari Rabu, 29 Januari 2025, di Washington. ((Foto AP/Alex Brandon))
Gugatan itu diajukan oleh kelompok yang mewakili pemegang TPS, termasuk beberapa yang tinggal di negara itu selama lebih dari dua dekade.
Pengacara di koran -koran pengadilan menulis atas nama para imigran bahwa mereka adalah “pekerja, petugas perawatan kesehatan, seniman dan bau” yang “mengandalkan TPS untuk memberikan bentuk keamanan manusia dasar – tempat yang stabil untuk hidup dan kesempatan untuk bekerja untuk mencari nafkah selama periode krisis parah di negara mereka yang berasal.”
Mereka berpendapat bahwa Noem menolak untuk memperpanjang mode TPS mereka, di bawah hukum, seharusnya diakses berdasarkan analisis individu dari masing -masing negara. Hakim menemukan bahwa Noem mungkin gagal dalam tahap menyelesaikan TPS pada faktor -faktor negara asal imigran.
Mereka juga mengatakan bahwa Nayyim memberi para migran periode yang singkat secara historis 60 hari sebelum mereka kehilangan posisi mereka di TPS. Pengacara mengatakan bahwa dia dan pejabat administrasi Trump lainnya normal menggunakan “investasi rasis” untuk menjelaskan keputusan TPS mereka.
Hakim Federal melarang kebijakan imigrasi Trump dalam keputusan yang mengejutkan tentang perlindungan tinggi

Presiden Donald Trump berbicara dengan Menteri Keamanan Internal Christie Sleep saat mereka berkeliling di Pusat Penahanan Migran, yang disebut “Alkatraz”, yang terletak di situs Bandara Pelatihan dan Transportasi di Ouchobi, Florida pada 1 Juli 2025. (Caaballero-Rynoleds/AFP Photography Via Getty Images)
Pengacara mati syahid oleh lusinan contoh Trump atau Nayyem yang menggambarkan migran sebagai anggota geng MS-13, pembunuh, teroris, dan orang-orang yang memiliki “gen” mereka untuk melakukan kejahatan. Mereka menunjuk saat debat viral Trump, di mana klaim yang tidak rumit bahwa para imigran Haiti sedang makan hewan peliharaan di Ohio.
TPS memberikan otoritas Kementerian Keamanan Nasional untuk mengizinkan para migran yang mungkin tidak memiliki status hukum untuk dilakukan sementara di Amerika Serikat karena keadaan luar biasa di negara asal mereka, seperti perang atau bencana alam.
Jaksa penuntut berpendapat bahwa hampir 61.000 orang akan kehilangan TPS sebagai akibat dari keputusan Nayyem, yang akan mengakhiri status hukum migran dan bekerja merah muda dan membuat mereka memenuhi syarat untuk dideportasi.
Administrasi Trump berpendapat bahwa sistem dasar yang memerintah TPS memberi sekretaris Kementerian Keamanan Nasional otoritas apresiasi untuk TPS NAMS dan bahwa Noem harus diizinkan untuk mengakhiri situasi menggunakan otoritas yang sama yang digunakan wali sebelumnya untuk memberikannya.

Menteri Keamanan Internal Christie Sleep mengadakan konferensi pers mengenai protes baru -baru ini di Los Angeles pada hari Kamis, 12 Juni 2025. (Foto AP/Etienne Laurent)
Klik di sini untuk mendapatkan aplikasi Fox News
Pada bulan Mei, Mahkamah Agung berdiri di hadapan administrasi Trump dalam masalah darurat yang terkait dengan kasus yang melibatkan TPS untuk Venezuela. Masalah ini sementara berhenti untuk perintah pengadilan, yang mengakhiri jalan untuk mengakhiri TPS sekitar 350.000 imigran.
Keputusan Thompson akan tetap ada hingga November, ketika sesi berikutnya dijadwalkan. Saya memberi tahu DHS Fox News Digital untuk mengajukan banding atas keputusan tersebut.
Ingin lebih banyak visi yang cerdas dari kotak masuk Anda? Berlangganan buletin mingguan kami untuk mendapatkan apa yang hanya terkait dengan lembaga AI, data dan pemimpin keamanan. Berlangganan sekarang
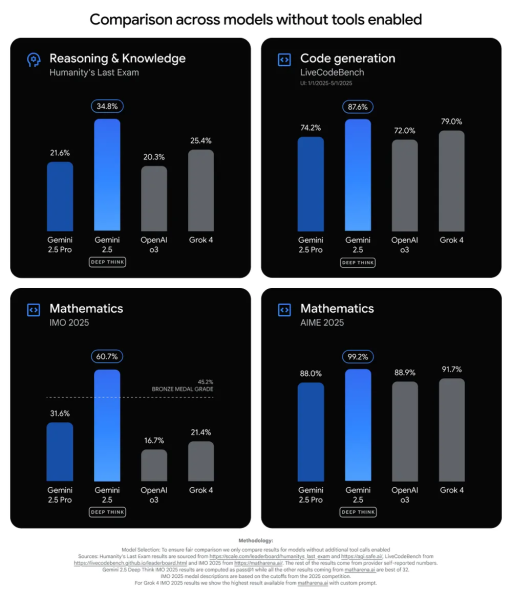
Google Secara resmi diluncurkan Gemini 2.5 Think Deep Perbedaan baru dalam model kecerdasan buatan yang dirancang untuk pemikiran yang lebih dalam dan masalah kompleks, yang menjadi berita utama surat kabar bulan lalu untuk memenangkan medali emas di Olimpiade Matematika Internasional (IMO)-pertama kali model kecerdasan buatan telah mencapai prestasi ini.
Tetapi, Sayangnya TIDAK Model pencocokan untuk medali emas. Faktanya, rilis “Bron” kurang kuat menurut publikasi blog Google dan Logan Kilpatric, yang menjadi dasar produk Google AI Studio.
menyukai Kilpatrick telah diterbitkan di jejaring sosial X: “Ini adalah variasi dalam model IMO Gold kami, yang lebih cepat dan lebih baik untuk penggunaan sehari -hari. Kami juga menawarkan model penuh IMO untuk sekelompok ahli matematika untuk menguji nilai kemampuan penuh.”
Tersedia sekarang melalui aplikasi seluler GeminiModel perunggu ini tersedia untuk pelanggan Rencana Amnesty International lebih mahal daripada AI di Google, AI UltraYang harganya $ 249,99 per bulan dengan promosi mulai 3 bulan dengan tarif berkurang $ 124,99 per bulan untuk pelanggan baru.
AI Impact Series kembali ke San Francisco – 5 Agustus
Tahap selanjutnya dari kecerdasan buatan di sini – apakah Anda siap? Bergabunglah dengan para pemimpin dari Block, GSK dan SAP untuk mengambil tampilan eksklusif tentang cara memulai kembali agen independen dari tugas alur kerja yayasan-dari keputusan dalam waktu yang sebenarnya untuk otomatisasi komprehensif.
Mengamankan tempat Anda sekarang – ruang terbatas: https://bit.ly/3guPlf
Google juga mengatakan dalam publikasi publikasi blog bahwa itu akan membawa pemikiran mendalam dengan dan tanpa integrasi alat untuk “laboratorium tepercaya” melalui antarmuka aplikasi API dalam beberapa minggu mendatang.
Mengapa “berpikir mendalam” sangat kuat
Gemini 2.5 Pikiran dalam tergantung pada keluarga Gemini dari model LLMS besar, menambahkan kemampuan baru yang bertujuan memikirkan masalah -masalah lanjutan.
Dia – dia Ini menggunakan teknik “pemikiran paralel” untuk mengeksplorasi banyak ide secara bersamaan dan termasuk belajar untuk meningkatkan kemampuan mereka untuk menyelesaikan masalah selangkah demi selangkah.
Modelnya Dirancang untuk kasus penggunaan yang mendapat manfaat dari pertimbangan yang diperluas, seperti pengujian tebakan, penelitian ilmiah, dan desain algoritma, Tugas pengulangan kreatif seperti instruksi perangkat lunak dan penyempurnaan desain.
Laboratorium pertama, termasuk matematikawan seperti Michelle Van Jarrel, yang digunakan untuk menyelidiki masalah yang belum diselesaikan dan menghasilkan bukti yang mungkin.
Pengguna dan Pakar Kekuatan dari Kecerdasan Buatan, Ethan Malik, Profesor Bisnis Warton di University of Pennsylvania, Itu juga diterbitkan di x Dia dapat mengambil klaim bahwa dia sering digunakan untuk menguji kemungkinan model baru – “Buat sesuatu yang dapat saya tempel di P5JS, yang akan membuat saya takjub dengan kecerdasannya dalam menciptakan sesuatu yang membutuhkan panel kontrol bintang di masa depan yang jauh” – dan dan Saya mengubahnya menjadi gambar tiga dimensi, pertama kali model apa pun melakukannya.
Standar Kinerja dan Kasus Penggunaan
Google menyoroti banyak area aplikasi utama untuk pemikiran yang mendalam:
- Matematika dan Sains: Model dapat mensimulasikan pemikiran tentang bukti kompleks, mengeksplorasi tebakan, dan interpretasi literatur ilmiah yang berat
- Desain pengkodean dan algoritma: Ini bekerja dengan baik pada tugas yang melibatkan badan kinerja, kompleksitas waktu, dan logika multi -langkah
- Pengembangan Kreatif: Dalam skenario desain seperti seni rubah atau antarmuka pengguna, pemikiran mendalam menunjukkan kekambuhan yang lebih kuat dan peningkatan detail
Model juga Melakukan penilaian standar seperti LiveCodebeench V6 (Untuk kemampuan pengkodean) Dan ujian terakhir untuk kemanusiaan (Cakupan matematika, sains dan pemikiran).
Dia – dia Gimini 2.5 Pro dan model yang bersaing seperti Openai’s GPT-4 dan Xai’s Grok 4 dilampaui Melalui margin bilangan ganda dalam beberapa kategori (pemikiran dan pengetahuan, menghasilkan kode, dan matematika IMO 2025).
Gemini 2.5 Think Deep versus Gemini 2.5 Pro
Sementara The Deep Think dan Gemini 2.5 Pro adalah bagian dari formulir Gemini 2.5, Google menempatkan Google Think Variabel dan analitik yang lebih mampuTerutama ketika datang ke pemikiran yang kompleks dan memecahkan banyak masalah.
Peningkatan ini berasal dari penggunaan Pemikiran paralel Dan Memperkuat teknik pembelajaranYang memungkinkan model untuk mensimulasikan musyawarah kognitif terdalam.
Dalam kontak resminya, Google menggambarkan pemikiran mendalam sebagai yang terbaik Berurusan dengan klaim yang akurat, mengeksplorasi banyak hipotesis, dan menghasilkan output yang lebih akurat. Ini didukung oleh perbandingan berdampingan dalam seni rubah, di mana pemikiran yang mendalam menambah lebih banyak tekstur, kesetiaan struktural, dan keragaman sintetis 2.5 Pro.
Perbaikan tidak hanya visual atau anekdotal. Google menyebutkan pemikiran yang dalam itu Gimini 2.5 Pro mengungguli beberapa standar teknis Tentang, menghasilkan kode, dan pengalaman domain di seluruh lapangan. Namun, keuntungan ini datang dengan gejala respons dan penerimaan langsung.
Ini adalah keruntuhan:
| Kemampuan / fitur | Gemini 2.5 Pro | Gemini 2.5 Pikiran mendalam |
|---|---|---|
| Kecepatan KESIMPULAN | Waktu transisi yang lebih cepat dan rendah | Perlambat, “waktu berpikir” yang diperpanjang |
| Kompleksitas pemikiran | sedang | Tinggi – menggunakan pemikiran paralel |
| Kedalaman dan kreativitas langsung | Bagus | Lebih detail dan akurat |
| Kinerja standar | kuat | canggih |
| Keamanan konten dan obyektivitas nada | Itu meningkatkan model lama | Meningkatkan lebih banyak peningkatan |
| Tingkat penolakan (klaim jinak) | minimum | lebih tinggi |
| Panjang output | standar | Mendukung tanggapan yang lebih lama |
| Seni / Desain Faksel adalah ketulusan | Struktur adegan dasar | Detail dan kekayaan yang ditingkatkan |
Google Perhatikan itu Tingkat penolakan yang tinggi dalam pemikiran mendalam Ini adalah bidang investigasi aktif. Ini dapat membatasi fleksibilitasnya dalam menangani pertanyaan misterius atau informal dibandingkan dengan 2,5 Pro. Sebaliknya, 2.5 Pro masih lebih cocok untuk pengguna yang memberikan prioritas Kecepatan dan responsTerutama untuk tugas yang lebih ringan untuk tujuan umum.
Perbedaan ini memungkinkan pengguna untuk memilih berdasarkan prioritas mereka: 2.5 pro untuk kecepatan dan likuiditasAtau Pikiran yang mendalam tentang kekakuan dan pemikiran.
Ini bukan model memenangkan medali emas, hanya perunggu
Pada bulan Juli, Google Deepmind menduduki puncak berita utama ketika ia mencapai versi yang lebih maju dari model Gemini Deep Think sebagai status resmi emas di sekolah menengah dunia-kompetisi matematika paling terkenal di dunia untuk siswa sekolah menengah.
memesan Lima dari enam masalah sulit dan menjadi Amnesty International pertama yang menerima tingkat emas dari IMO.
Demis Hassabis, CEO Google DeepMind, telah mengumumkan pencapaian X, dengan mengatakan bahwa model tersebut telah memecahkan masalah dari satu sisi tanpa kebutuhan untuk terjemahan untuk membangun kalimat pemrograman total.
Dewan IMO mengkonfirmasi bahwa model tersebut mencetak 35 poin dari 42 poin potensial, jauh lebih tinggi dari ambang emas. Gemini 2.5 Solusi Think Deep Think Deskripsi Kepala Kompetisi, Gregor Dolinear Jelas dan akurat dan dalam banyak kasus, Yang paling mudah ditindaklanjuti pada pesaing manusia.
Namun, Gueini 2.5 Deep Think, yang dirilis kepada pengguna tidak sama dengan model kompetisi, sebaliknya, tampaknya kurang kinerja tetapi tampaknya lebih cepat.
Bagaimana cara berpikir dalam sekarang
Gemini 2.5 Berpikir Mendalam Tersedia secara eksklusif di aplikasi seluler Google Gemini untuk iOS dan Android saat ini untuk pengguna di Paket Google AI UltraBagian dari koleksi langganan Google One, dengan harga sebagai berikut.
- Penawaran Promosi: 124,99 dolar per bulan selama 3 bulan, lalu mulai …
- Tingkat Standar: 249,99 dolar/bulan
- Fitur Termasuk: 30 TB Penyimpanan, Akses ke Gemini dengan Deep Think dan Veo 3, serta alat -alat seperti Flow, Westerk dan 12.500 kredit bulanan kecerdasan buatan
Pelanggan dapat mengaktifkan pemikiran mendalam di aplikasi Gemini dengan memilih model 2.5 Pro dan beralih opsi “Berpikir Deep”.
Ini mendukung sejumlah klaim yang tetap setiap hari dan dikombinasikan dengan kemampuan seperti mengimplementasikan perangkat lunak dan penelitian di Google. Model ini juga menghasilkan output yang lebih lama dan lebih rinci dibandingkan dengan versi standar.
Paket Google AI Pro tingkat rendah, dengan harga $ 19,99 per bulan (dengan pengalaman bebas), tidak termasuk pemikiran yang mendalam, atau Gemini AI gratis.
Mengapa para pembuat keputusan teknis dari lembaga -lembaga itu menjadi perhatian?
Gemini 2.5 Think Deep mewakili aplikasi praktis untuk guru pencarian utama.
Dia – dia Lembaga dan lembaga diizinkan untuk memanfaatkan model Olympiad media dan membuat mereka bergabung dengan karyawan mereka, Dan jika hanya melalui akun pengguna individual sekarang.
Bagi para peneliti yang menerima model IMO penuh, ia menawarkan sekilas masa depan kecerdasan buatan kooperatif dalam matematika. Untuk pelanggan yang unggul, Deep Think memberikan langkah kuat menuju bantuan kecerdasan buatan, yang sekarang Anda jalankan di tangan mereka.
Tautan sumber

 Berita8 tahun ago
Berita8 tahun agoThese ’90s fashion trends are making a comeback in 2017
- Berita8 tahun ago
The final 6 ‘Game of Thrones’ episodes might feel like a full season
- Berita8 tahun ago
According to Dior Couture, this taboo fashion accessory is back
- Berita8 tahun ago
The old and New Edition cast comes together to perform
- Berita8 tahun ago
Phillies’ Aaron Altherr makes mind-boggling barehanded play
- Berita8 tahun ago
Uber and Lyft are finally available in all of New York State
- Berita8 tahun ago
Disney’s live-action Aladdin finally finds its stars
- Berita8 tahun ago
Mod turns ‘Counter-Strike’ into a ‘Tekken’ clone with fighting chickens

